本文是对Logback使用与配置的学习与整理。
在Java日志工具类一文中梳理了Java中打印日志常用的工具,目前常用的日志实现主要是logback和log4j2。
从性能的角度看,log4j2比logback要优秀,特别是异步输出日志的方式下,详见日志框架,选择Logback Or Log4j2?。不过一方面考虑到我们的场景下日志性能对整个业务性能的影响较小,另一方面logback是Springboot默认的日志工具。因此一直以来我都选择logback作为日志输出的工具。
之前对logback的使用都处于边查边用的状态。此次为了对我们项目的日志进行整理,系统学习了logback的使用。本文就是学习的一个记录。
logback的使用
使用logback很简单,以maven工程为例,只要在pom.xml文件中引入logback的依赖即可:
1 | <dependency> |
使用logback非常简单:
1 | public class Demo1 { |
输出内容如下:
1 | 17:06:07.613 [main] DEBUG love.wangqi.Demo1 - log1 |
Logger在创建的时候需要指定名称。如果传入的是一个类,那么就以这个类的全限定名作为这个Logger的名称。注意Logger的命名是大小写敏感的。
Logger根据命名遵循以下规则组成层次结构:
如果一个logger的名字加上一个
.作为另一个logger名字的前缀,那么该logger就是另一个logger的祖先。如果一个logger与另一个logger之间没有其他的logger,则该logger就是另一个logger的父级。
例如:名为com.foo的logger是名为com.foo.Bar的logger的父级。名为java的logger是名为java.util的父级,是名为java.util.Vector的祖先。
Logger被分为不同的级别:
TRACEDEBUGINFOWARNERROR
如果一个给定的Logger没有指定级别,那么它就会继承离它最近的一个祖先的级别。如果所有祖先都没有指定级别,则继承root logger的级别。
日志的级别由打印的方法决定。只有一条日志的级别大于等于Logger的级别,该条日志才可以被打印出来。
各级别的排序为TRACE<DEBUG<INFO<WARN<ERROR
举例来说,L的Logger的一个实例,级别为INFO。只有调用L.info()、L.warn()、L.error()方法输出的内容才会被日志记录,因为这些日志的级别高于INFO,而L.trace()、L.debug()方法输出的内容会被忽略。
logback的配置
上面我们看到,logback可以不经过任何配置直接使用。实际上logback是使用了一个默认的配置,可以使用代码输出这个过程:
1 | public class Demo1 { |
输出内容如下:
1 | 17:13:48.443 [main] DEBUG love.wangqi.Demo1 - log1 |
实际上,logback在初始化时会经历以下步骤:
- 在类路径下寻找名为
logback-test.xml的文件 - 如果没有找到,
logback会继续寻找名为logback.grooxy的文件 - 如果没有找到,
logback会继续寻找名为logback.xml的文件 - 如果没有找到,将会通过JDK提供的
ServiceLoader工具在类路径下寻找文件META-INFO/services/ch.qos.logback.classic.spi.Configurator,该文件的内容为实现了Configurator接口的实现类的全限定类名。 - 如果以上都没有成功,
logback会通过BasicConfigurator为自己进行配置,并且日志将会全部在控制台打印出来。
最后一步生成的默认配置的日志级别为DEBUG,因此我们看到TRACE级别的日志没有被打印到控制台。
实际项目中,我们肯定会定义一个配置文件来代替logback默认的配置。
logback以及其他的日志工具比如log4j、log4j2都通过配置文件来定义日志的行为。这样的好处是只需要调整配置文件就可以改变日志打印的行为:调整日志级别,禁用一部分日志,改变日志输出的目的地。而不需要重新编译整个工程的代码。
logback配置文件的基本格式如下:
1 | <configuration> |
最基本的结构为<configuration>元素,包含0个或多个<appender>元素,其后跟0个或多个<logger>元素,其后再跟最多一个<root>元素。基本结构图如下:
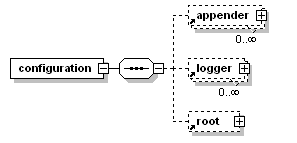
logger
<logger>标签用于细化logger的配置。必须包含一个name属性,一个可选的level属性,一个可选的additivity属性。additivity的值为true或false。level的值为TRACE、DEBUG、INFO、ERROR、ALL、OFF、INHERITED、NULL。当level的值为INHERITED或NULL时,将会强制logger继承上一层的级别。
<logger>标签包含0个或多个<appender-ref>元素。每一个appender通过这种方式被添加到logger上。
root
root logger通过<root>标签来配置。它只支持一个属性level。level的值为TRACE、DEBUG、INFO、ERROR、ALL、OFF,但是不能设置为INHERITED、NULL。
和<logger>标签类似,<root>可以包含0个或多个<appender-ref>元素。
appender
<appender>标签用于配置logback中的Appender组件。Appender是logback中负责日志写入的组件。
<appender>标签需要两个强制的属性name和class,name属性用来指定appender的名字,class属性需要指定类的全限定名用于实例化。<appender>元素可以包含0或一个<layout>元素,0或多个<encoder>元素,0或多个<filter>元素。结构图如下:
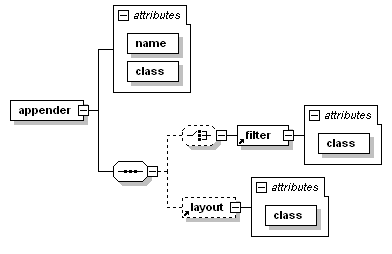
logback内置了多种appender可以使用,下面介绍几个常用的appender:
OutputStreamAppender
OutputStreamAppender将事件附加到java.io.OutputStream上。这个类提供了其他appender构建的基础服务,用户无法直接配置OutputStreamAppender。它是ConsoleAppender、FileAppender、RollingFileAppender三个appender的父类。FileAppender又是RollingFileAppender的父类。属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| encoder | Encoder | 决定通过哪种方式将事件写入OutputStreamAppender |
| immediateFlush | boolean | immediateFlush配置日志是否被立即写入,默认为true。立即写入可以保证日志的安全,即使程序没有正确关闭日志也不会丢失。但是同时也降低了日志写入的性能 |
ConsoleAppender
ConsoleAppender将日志事件输出到控制台。属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| encoder | Encoder | 参见OutputStreamAppender |
| target | String | System.out或System.err。默认为System.out |
| withJansi | boolean | withJansi的默认值为false。设置withJansi为true可以激活Jansi在windows使用ANSI彩色代码。在windows上如果设置为true,你应该将org.fusesource.jansi:jansi:1.9这个jar包放到classpath下。基于Unix实现的操作系统,像Linux、Max OS X都默认支持ANSI彩色代码。 |
FileAppender
FileAppender是OutputStreamAppender的子类,将日志事件输出到文件中。属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| append | boolean | 如果为true,日志事件会被追加到文件中,否则的话,文件会被截断。默认为true |
| encoder | Encoder | 参见OutputStreamAppender |
| file | String | 要写入文件的名称。如果文件不存在,则新建。 |
| prudent | boolean | 严格模式,默认为false,严格模式将日志安全的写入指定文件。严格模式依赖排他锁,它的成本很高,特别是日志文件位于网络文件系统上时。 |
RollingFileAppender
RollingFileAppender继承自FileAppender,具有轮转文件的功能。即在满足特定条件后,将日志输出到另外一个文件。
与RollingFileAppender进行交互的有两个重要的子组件。一个是RollingPolicy,它负责日志轮转的功能。另一个是TriggeringPolicy,它负责日志轮转的时机。所以RollingPolicy负责发生什么,TriggeringPolicy负责什么时候发生。
为了让RollingFileAppender生效,必须同时设置RollingPolicy和TriggeringPolicy。但是,如果RollingPolicy也实现了TriggeringPolicy接口,那么只需要设置前一个就好了。
RollingFileAppender属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| file | String | 参见FileAppender |
| append | boolean | 参见FileAppender |
| encoder | Encoder | 参见OutputStreamAppender |
| rollingPolicy | RollingPolicy | 当轮转发生时,指定RollingFileAppender的行为 |
| triggeringPolicy | TriggeringPolicy | 告诉RollingFileAppender什么时候发生轮转行为 |
| prudent | boolean | FixedWindowRollingPolicy不支持该属性。RollingFileAppender在使用严格模式时要与TimeBasedRollingPolicy结合使用,但是有两个限制:在严格模式下,不支持也不允许文件压缩;不能对FileAppender的file属性进行设置。 |
Rolling Policy
RollingPolicy负责轮转的方式:移动文件以及对文件改名。
TimeBasedRollingPolicy
TimeBasedRollingPolicy是最常用的轮转策略,它基于时间来定义轮转策略。TimeBasedRollingPolicy即负责轮转的行为,也负责触发轮转,它同时实现了RollingPolicy和TriggeringPolicy接口。
属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| fileNamePattern | String | 该属性定义了轮转时的属性名。 |
| maxHistory | int | 可选属性。控制最多保留多少数量的归档文件,超出这个数量后旧的归档文件将被异步删除。 |
| totalSizeCap | int | 可选属性。控制所有归档文件的总大小。达到这个大小后,旧的归档文件将会被异步删除。使用这个属性时还需要设置maxHistory属性,maxHistory将会被作为第一条件,该属性作为第二条件 |
| cleanHistoryOnStart | boolean | 默认为false。如果设置为true,那么在appender启动的时候,归档文件将会被删除。 |
TimeBasedRollingPolicy的轮转周期是通过fileNamePattern推断出来的。fileNamePattern的值由文件名加上一个%d的占位符,%d应该包含java.text.SimpleDateFormat中规定的日期格式,如果省略掉这个日期格式,默认为yyyy-MM-dd。
可以指定多个%d,但是只能有一个是主要的,用于推断轮转周期。其他的%d占位符必须通过aux标记为辅助。比如/var/log/%d{yyyy/MM, aux}/myapplication.%d{yyyy-MM-dd}.log,通过年月来管理日志文件夹,但是轮转周期在每天晚上零点。
如果想要根据时区而不是主机的时钟来轮转日志,可以通过以下方式来指定一个时区:aFloder/test.%d{yyyy-MM-dd-HH, UTC}.log
TimeBasedRollingPolicy通过%d中的日期来确定轮转周期:
/wombat/foo.%d:每天晚上零点轮转。因为省略了日期格式,默认为yyyy-MM-dd/wombat/%d{yyyy/MM}/foo.txt:每个月开始的时候轮转/wombat/foo.%d{yyyy-ww}.log:每周的第一天轮转,取决于时区/wombat/foo%d{yyyy-MM-dd_HH}.log:每小时轮转/wombat/foo%d{yyyy-MM-dd_HH-mm}.log:每分钟轮转/wombat/foo%d{yyyy-MM-dd_HH-mm, UTC}.log:每分钟轮转,不过时间格式是UTC/foo/%d{yyyy-MM, aux}/%d.log:每天轮转。归档文件在包含年月的文件夹下
TimeBasedRollingPolicy支持文件自动压缩。如果fileNamePattern以.gz或者.zip结尾,将会启动这个特性。
/wombat/foo.%d.gz:每天晚上零点轮转,自动将归档文件压缩成GZIP格式
fileNamePattern有两个目的。logback通过该属性可以进行周期性的轮转并且得到每个归档文件的名字。注意,两种不同的pattern可能会有相同的轮转周期:yyyy-MM与yyyy@MM同样都是按月轮转,但是归档文件最终的名字不一样。
通过设置file属性,你可以将活动日志文件的路径与归档文件的路径分隔开来。日志将会一直输出到通过file属性指定的文件中,并且不会随着时间而改变。但是如果选择忽略file属性,活动日志的名字将会根据fileNamePattern的值在每个周期内变化。
maxHistory控制归档文件保留的最大数目,并且删除旧的文件。例如你指定按月轮转,并设定maxHistory的值为6,那么6个月之内的归档文件会被保留,大于6个月的文件将会被删除。当旧文件被移除时,为文件归档而创建的文件夹在适当时候也会被移除。
注意:轮转并不是时间驱动的,而是依赖日志事件。假设fileNamePattern的值为yyyy-MM-dd(按天轮转),如果没有日志事件到来则晚上零点日志并不会发生轮转,如果10分钟之后第一个日志事件到达此时才会触发轮转。因此,依赖日志事件的到达速度,轮转可能会有延迟。
下面是RollingFileAppender与TimeBasedRollingPolicy结合使用的例子:
1 | <configuration> |
SizeAndTimeBasedRollingPolicy
SizeAndTimeBasedRollingPolicy既可以按时轮转,又可以限制每个日志文件的大小。
示例如下:
1 | <configuration debug="true"> |
这里有两个限制日志大小的标签:<maxFileSize>标签用于限制单个日志文件的大小,<totalSizeCap>标签限制归档文件总的大小。
SizeAndTimeBasedRollingPolicy除了%d之外还需要%i,这两个占位符都是强制要求的。在当前时间还没有到达周期轮转之前,日志文件达到了maxFileSize指定的大小就会进行归档,递增索引从0开始。
FixedWindowRollingPolicy
FixedWindowRollingPolicy根据固定窗口算法重命名文件。属性描述如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| minIndex | int | 窗口索引的下界 |
| maxIndex | int | 窗口索引的上界 |
| fileNamePattern | String | FixedWindowRollingPolicy在重命名日志文件时将会根据这个属性来命名。它必须包含一个%i的占位符,该占位符指明了窗口索引的值应该插入的位置。 |
使用示例如下:
1 | <configuration> |
注意file属性是强制的,即使它包含了一些跟fileNamePattern属性相同的信息。
上面配置的运行模式如下:
| 轮转数目 | 当前输出文件 | 归档日志文件 | 描述 |
|---|---|---|---|
| 0 | test.log | - | 还没有到轮转周期,logback将日志输出到初始文件 |
| 1 | test.log | tests.1.log.zip | 第一次轮转,test.log被压缩为tests.1.log.zip。一个新的test.log文件将会被创建并成为当前输出文件 |
| 2 | test.log | tests.1.log.zip tests.2.log.zip |
第二次轮转,tests.1.log.zip被重命名为tests.2.log.zip,test.log被压缩为tests.1.log.zip。一个新的test.log文件被创建并成为当前输出文件 |
| 3 | test.log | tests.1.log.zip tests.2.log.zip tests.3.log.zip |
第三次轮转,tests.2.log.zip被重命名为tests.3.log.zip,tests.1.log.zip被重命名为tests.2.log.zip,test.log被压缩为tests.1.log.zip。一个新的test.log文件被创建并成为当前输出文件 |
| 4 | test.log | tests.1.log.zip tests.2.log.zip tests.3.log.zip |
本次以及后续的轮转中,将会删除tests.3.log.zip文件,其他文件的重命名操作跟之前的步骤一样。将会一直只有三个归档文件以及一个活跃的日志文件。 |
Triggering Policy
TriggeringPolicy的实现用于通知RollingFileAppender何时轮转。
TimeBasedRollingPolicy是使用最广泛的触发策略。也可以用作轮转策略来使用。
SizeBasedTriggeringPolicy
SizeBasedTriggeringPolicy观察当前活动文件的大小,如果已经大于指定的值,它会给RollingFileAppender发一个信号触发当前活动文件的轮转。
SizeBasedTriggeringPolicy只接受maxFileSize这一个参数,它的默认值是10MB。
maxFileSize可以为字节、千字节、兆字节、千兆字节,通过在数值后面指定一个后缀KB、MB、GB。
其他appender
前面介绍的appender只能将日志输出到本地资源,还有一些可以将日志输出到网络中的appender。
SocketAppender:可以将ILoggingEvent实例序列化后再传输到远端机器,日志事件以明文发送。SSLSocketAppender:和SocketAppender类似,日志事件通过安全通道传输。SMTPAppender:收集日志事件到一个或多个固定大小的缓冲区中,当用户指定的事件发生时,将从缓冲区中取出适当的内容进行发送。SMTP邮件是异步发送的。默认情况下,当日志的级别为ERROR时,邮件发送将会被触发。DBAppender:以一种独立于Java语言的方式将日志事件插入到三张数据库表中。SyslogAppender:将消息发送给远程的syslog守护线程。SiftingAppender:根据给定的运行时属性分离或者过滤日志。AsyncAppender:异步地打印ILoggingEvent。它仅仅是作为一个事件调度器存在,因此必须调用其他的appender来完成操作。
encoder
encoder将日志事件转换为字节数组,同时将字节数组写入到一个OutputStream中。
在之前的版本中,用户需要在FileAppender中内置一个PatternLayout,新版本中FileAppender以及子类需要一个encoder而不是layout。
为了兼容之前layout的配置,logback引入了PatternLayoutEncoder来在encoder和layout之间进行交互。
无论FileAppender还是其子类通过PatternLayout来进行配置,都必须使用PatternLayoutEncoder来代替。
PatternLayout
layout是logback的组件,负责将日志事件转换为字符串。
logback内置了一个可以灵活配置的layout叫做PatternLayout。通过调整PatternLayout的转换模式来进行定制。
转换模式由字面量和格式控制表达式也叫做转换说明符组成。你可以在转换模式中自由地插入字面量。每一个转换说明符由一个百分号%开始,后面跟随可选的格式修改器,以及转换字符与括号括起来的可选参数。转换字符需要转换的字段,如:logger的名字,日志级别,日期以及线程名。格式修改器控制字段的宽度,间距以及左右对齐。
转换字符
转换字符与它们的可选参数如下:
logger
1 | c{length} |
输出logger的名字作为日志事件的来源。转换字符接收一个整数作为它的唯一参数。转换器的简写算法将会缩短logger的名字,但是通常不会丢失重要的信息。设置length的值为0是唯一的例外,它只会保留logger名字最右边的部分。其他情况下,logger名字最右边的部分不会被简写,即使它的长度比length的值要大,其他部分可能会被缩短为一个字符,但是永远不会被移除。示例如下:
| 转换说明符 | 日志名字 | 结果 |
|---|---|---|
| %logger | mainPackage.sub.sample.Bar | mainPackage.sub.sample.Bar |
| %logger{0} | mainPackage.sub.sample.Bar | Bar |
| %logger{5} | mainPackage.sub.sample.Bar | m.s.s.Bar |
| %logger{10} | mainPackage.sub.sample.Bar | m.s.s.Bar |
| %logger{15} | mainPackage.sub.sample.Bar | m.s.sample.Bar |
| %logger{16} | mainPackage.sub.sample.Bar | m.sub.sample.Bar |
| %logger{26} | mainPackage.sub.sample.Bar | mainPackage.sub.sample.Bar |
class
1 | C{length} |
输出日志请求类的全限定名称。跟%logger转换符一样,它也可以接收一个整型的可选参数去缩短类名。0表示特殊含义,在打印类名时将不会输出包的前缀名。默认表示打印类的全限定名。
生成调用者类的信息并不是特别快。因此,应该避免使用,除非执行速度不是问题。
contextName
1 | contextName |
输出日志事件附加到logger的上下文(context)的名称
date
1 | d{pattern} |
用于输出日志事件的日期。pattern参数用于指定日志的格式,如果没有指定日期格式,默认为ISO8601类型。
timezone用于执行时区。如果没有指定时区参数,则默认使用Java平台所在主机的时区。如果指定的时区不能被识别或者拼写错误,则会指定时区为GMT。
常见错误:对于HH:mm:ss,SSS模式,逗号会被解析为分隔符,所以最终会被解析为HH:mm:ss,SSS会被当做时区。如果在日期模式中使用逗号,那么可以用双引号将日期模式包裹起来:%date{"HH:mm:ss,SSS"}。
file
1 | F |
输出发出日志请求的Java源文件名。
生成文件的信息不是特别快,因此,应该避免使用,除非速度不是问题。
caller
1 | caller{depth} |
输出日志的调用者所在的位置信息。
位置信息依赖JVM的实现,通常由以下几部分组成:调用方法的全限定名、调用者的来源、圆括号括起来的文件名与行号。
caller转换符接收一个depth整型参数,用来配置展示信息的深度。
例如,%caller{2}展示信息如下:
1 | 0 [main] DEBUG - logging statement |
%caller{3}展示信息如下:
1 | 16 [main] DEBUG - logging statement |
还可以传入一个范围来配置展示信息的深度,比如%caller{1..2}展示信息如下:
1 | 0 [main] DEBUG - logging statement |
还可以传入多个evaluator。比如%caller{3, CALLER_DISPLAY_EVAL},只有CALLER_DISPLAY_EVAL返回一个肯定的答案,才会显示3行调用栈。
Evaluators下面会描述。
line
1 | L |
输出日志请求所在的行号。
生成行号不是特别快。因此,不建议使用,除非生成速度不是问题。
message
1 | m |
输出与日志事件相关联的,由应用程序提供的日志信息。
method
1 | M |
输出日志请求的方法名。
生成方法名不是特别快,因此,应该避免使用,除非生成速度不是问题
n
1 | n |
输出平台所依赖的行分隔字符。
转换字符提供了像\n或\r\n一样的转换效果。因此指定行分隔符是首选的指定方式。
level
1 | p |
输出日志事件的级别。
relative
1 | r |
输出应用程序启动到创建日志事件所花费的毫秒数。
thread
1 | t |
输出生成日志事件的线程名。
mdc
1 | X{key:-defaultVal} |
输出生成日志事件的线程的MDC(mapped diagnostic context)。
如果MDC转换字符后面跟着用花括号括起来的key,例如%MDC{userid},那么userid所对应MDC的值将会输出。如果该值为null,那么通过:-指定的默认值将会输出。如果没有指定默认值,那么将会输出空字符串。
如果没有指定的key,那么MDC的整个内容将会以key1=val1,key2=val2的格式输出。
exception/throwable
1 | ex{depth} |
输出日志事件关联的异常栈。默认输出整个栈。
throwable转换字符可以接受以下参数来配置栈的深度:short(打印异常栈的第一行)、full(打印整个异常栈),其他整数(打印指定行数的异常栈)。示例如下:
%ex:
1 | mainPackage.foo.bar.TestException: Houston we have a problem |
%ex{short}:
1 | mainPackage.foo.bar.TestException: Houston we have a problem |
%ex{full}:
1 | mainPackage.foo.bar.TestException: Houston we have a problem |
%ex{2}:
1 | mainPackage.foo.bar.TestException: Houston we have a problem |
也可以传入多个evaluator,比如%ex{full, EX_DISPLAY_EVAL},只有当EX_DISPLAY_EVAL返回否定答案时,才会输出全部的堆栈信息。
如果你没有指定%throwable或者其他跟throwable相关的转换字符,那么PatternLayout会在最后一个转换字符加上这个,因为堆栈信息非常重要。如果你不想展示堆栈信息,那么可以使用%nopex可以替代%throwable。
xException/xThrowable
1 | xEx{depth} |
跟%throwable类似,只不过多了类的包信息。
在每个堆栈信息的末尾,多了包含jar文件的字符串,后面再加上具体的实现版本。如果该信息不确定,那么类的包信息前面会有一个波浪线(~)。示例如下:
1 | java.lang.NullPointerException |
nopexception
1 | nopex |
这个转换字符不会输出任何数据,因此它可以用来有效忽略异常信息。
%nopex转换字符允许用户重写PatternLayout内部的安全机制,该机制将会在没有指定其他处理异常的转换字符时,默认添加%xThrowable。
marker
1 | marker |
输出与日志请求相关的标签。
一旦标签包含子标签,那么转换器将会根据下面的格式展示父标签与子标签。
1 | parentName [ child1, child2 ] |
property
1 | property{key} |
输出属性key所对应的值。如果key在logger context中没有找到,那么将会去系统属性中找。
key没有默认值,如果缺失,则会展示Property_HAS_NO_KEY的错误信息。
replace
1 | replace(p){r,t} |
在子模式p产生的字符中,将所有出现正则表达式r的地方替换为t。例如,%replace(%msg){'\s', ''}将会移除事件消息中所有空格。
模式p可以是任意复杂的甚至多个转换字符组成。例如,%replace(%logger %msg){'\.', '/'}将会替换logger以及消息中所有的.为/。
rootException
1 | rEx{depth} |
输出与日志事件相关的堆栈信息,根异常将会首先输出,示例如下:
1 | java.lang.NullPointerException |
%rootException跟%xException类似,也允许一些可选的参数,包括depth和evaluators。它也会输出包信息。简单来说,%rootException跟%xException非常类似,仅仅是异常输出的顺序完全相反。
格式修改器
格式修改器用于对每个数据字段进行对齐,以及更改最大最小宽度。
可选的格式修改器放在百分号跟转换字符之间。
第一个可选的格式修改器是左对齐标志,也就是减号-字符。接下来是最小字段宽度修改器,它是一个十进制常量,表示输出至少多少个字符。如果字段包含很少的数据,它会选择填充左边或者右边,直到满足最少宽度。默认是填充左边(右对齐),但是你可以通过左对齐标志来对右边进行填充。填充字符为空格。如果字段的数据大于最小字段的宽度,会自动扩容去容纳所有的数据。字段的数据永远不会被截断。
这个行为可以通过使用最大字段宽度修改器来改变,它通过一个.后面跟着一个十进制常量来指定。如果字段的数据长度大于最大字段的宽度,那么会从数据字段的开头移除多余的字符。举个例子,如果最大字段的宽度是8,数据长度是10个字符的长度,那么开头的两个字符将会被丢弃。
如果想从后面开始截断,可以在.后面增加一个-号。如果是这样的话,最大字段宽度是8,数据长度是10个字符的长度,那么最后两个字符将会被丢弃。
下面是各种格式修改器的例子:
| 格式修改器 | 左对齐 | 最小宽度 | 最大宽度 | 备注 |
|---|---|---|---|---|
| %20logger | false | 20 | none | 如果logger的名字小于20个字符的长度,那么会在左边填充空格 |
| %-20logger | true | 20 | none | 如果logger的名字小于20个字符的长度,那么会在右边填充空格 |
| %.30logger | NA | none | 30 | 如果logger的名字大于30个字符的长度,那么从前面开始截断 |
| %20.30logger | false | 20 | 30 | 如果logger的名字小于20个字符的长度,那么会从左边填充空格。但是如果logger的名字大于30个字符,将会从前面开始截断 |
| %-20.30logger | true | 20 | 30 | 如果logger的名字小于20个字符的长度,那么会从右边填充空格。但是如果logger的名字大于30个字符,将会从前面开始截断 |
| %.-30logger | NA | none | 30 | 如果logger的名字大于30个字符的长度,那么从后面开始截断 |
下面的表格列出了格式修改器阶段的例子。注意综括号[]不是输出结果的一部分,它只是用来区分输出的长度。
| 格式修改器 | logger的名字 | 结果 |
|---|---|---|
| [%20.20logger] | main.Name | [ main.Name] |
| [%-20.20logger] | main.Name | [main.Name ] |
| [%10.10logger] | main.foo.foo.bar.Name | [o.bar.Name] |
| [%10.-10logger] | main.foo.foo.bar.Name | [main.foo.f] |
使用格式修改器可以来缩短日志等级的表示,比如%.-1level,将TRACE、DEBUG、WARN、INFO、ERROR的日志等级表示方式输出为T、D、W、I、E。
在logback里,模式字符串中的圆括号被看做是分组标记。因此,它能够对子模式进行分组,并且直接对子模式进行格式化。
例如:
1 | %-30(%d{HH:mm:ss.SSS} [%thread]) %-5level %logger{32} - %msg%n |
将会对子模式%d{HH:mm:ss.SSS} [%thread]进行分组输出,为了在少于30个字符时进行右填充。
使用分组标记可以对子模式进行着色。在1.0.5版本,PatternLayout可以识别%black, %red, %green, %yellow, %blue, %magenta,%cyan, %white, %gray, %boldRed,%boldGreen,%boldYellow, %boldBlue, %boldMagenta, %boldCyan, %boldWhite 以及%highlight作为转换字符。这些转换字符都还可以包含一个子模式。任何被颜色转换字符包裹的子模式都会通过指定的颜色输出。
1 | <configuration debug="true"> |
filter
Appender实例可以添加一个或多个过滤器,来过滤日志事件,例如日志消息的内容、MDC的内容、事件或者日志的其他部分。
logback有两种类型的过滤器,regular过滤器以及turbo过滤器。
RegularFilters
regular过滤器继承自Filter这个抽象类。过滤器通过一个有序列表进行管理,并且基于三元逻辑。每个过滤器的decide(ILoggingEvent event)被依次调用。这个方法返回FilterReply枚举值中的一个,DENY、NEUTRAL、ACCEPT:
- 如果
decide()方法返回DENY,那么日志事件会被丢弃掉,并且不会考虑后续的过滤器。 - 如果返回值是
NEUTRAL,那么才会考虑后续的过滤器。如果没有其他的过滤器了,那么日志事件会被正常处理。 - 如果返回值是
ACCEPT,那么会跳过剩下的过滤器而直接被处理。
levelFilter
LevelFilter基于级别来过滤日志事件。如果事件的级别与配置的级别相等,过滤器会根据配置的onMatch与onMismatch属性,接受或者拒绝事件。示例:
1 | <configuration> |
ThresholdFilter
ThresholdFilter基于给定的临界值来过滤事件。如果事件的级别等于或高于给定的临界值,当调用decide()时,ThresholdFilter将会返回NEUTRAL。但是事件的级别低于临界值将会被拒绝。示例:
1 | <configuration> |
EvaluatorFilter
EvaluatorFilter是一个通用的过滤器,它封装了一个EventEvaluator。EventEvaluator根据给定的标准来评估给定的事件是否符合标准。在match和mismatch的情况下,EvaluatorFilter将会返回onMatch或onMismatch指定的值。
GEventEvaluator
GEventEvaluator是EventEvaluator具体的实现,它采用Groovy表达式作为评估的标准。
JaninoEventEvaluator
JaninoEventEvaluator接受任意返回布尔值的Java代码块作为评判标准。我们把这种Java布尔表达式称为评估表达式。
TurboFilters
TurboFilter对象都继承TurboFilter抽象类。TurboFilter对象被绑定在logger上下文中。在使用给定的appender以及每次发出的日志请求都会调用TurboFilter对象。因此,TurboFilter可以为日志事件提供高性能的过滤,即使在事件被创建之前。
logback内置了几个TurboFilter:
MDCFilter用来检查给定的值在MDC中是否存在。DynamicThresholdFilter根据MDC key/level相关的阈值来进行过滤MarkerFilter用来检查日志请求中指定的marker是否存在DuplicateMessageFilter用来检测重复的消息,在重复了一定次数之后,丢弃掉重复的消息。
定期扫描配置文件
logback可以定时扫描配置文件,发生更改时自动加载:在<configuration>标签上添加scan=true属性。默认情况下,一分钟扫描一次配置文件。通过<configuration>标签上的scanPeriod属性可以指定扫描周期。扫描周期可以是毫秒、秒、分钟或者小时。
设置context的名字
每一个logger都会附加到一个logger context上去。默认这个logger context的名字的default。如果设置过一次就不能再设置。示例:
1 | <configuration> |
变量替换
logback支持变量的定义以及替换。变量有它的作用域,可以在配置文件中,外部文件中,外部资源文件中,甚至动态定义。
比如可以在配置文件的开始定义一个变量,之后再使用${}符号应用这个变量:
1 | <configuration> |
也可以引用系统变量中定义的变量:
1 | <configuration> |
通过如下方式定义变量:
1 | java -DUSER_HOME="/data/logs" MyApp3 |
当需要定义多个变量时,可以将这些变量放到一个单独的文件中:
1 | <configuration> |
这个配置文件包含了一个对外部文件的引用:variables1.properties,这个外部文件包含一个变量:
1 | USER_HOME=/data/logs |
也可以引用classpath下的资源文件:
1 | <configuration> |
作用域
属性的作用域分别为:
- 本地(
local scope):本地范围内的属性存在配置文件的加载过程中。配置文件每加载一次,变量就会被重新定义一次 - 上下文(
context scope):上下文范围内的属性会一直存在,直到上下文被清除 - 系统(
system scope):系统范围内的属性,会插入到JVM的系统属性中,跟随JVM一同消亡。
在进行变量替换的时候,会先从本地范围去找,再从上下文去找,再从系统属性中去找,最后会去系统的环境变量中去找。
可以通过<property>、<define>、<insertFromJNDI>元素的scope属性来设置变量的作用范围。scope属性可能的值为:local、context、system。默认为local。
1 | <configuration> |
在某些情况下,如果某个变量没有被声明,或者为空,默认值非常有用。默认值可以通过:-来指定。例如:假设变量aName没有被定义,${aName:-golden}会被解释成golden。
变量的名字、默认值、以及值都可以引用其他的变量。
一个变量的值可以包含对其他变量的引用:
1 | USER_HOME=/data/logs |
变量的名字可以包含对其他变量的引用。例如:如果变量userid=alice,那么${${userid}.password}就是对变量名alice.password的引用。
一个变量的默认值可以引用另一个变量。例如:假设变量id没有被定义,变量userid的值为alice,那么表达式${id:-${userid}}的值为alice
HOSTNAME在配置期间会被自动定义为上下文范围内。CONTEXT_NAME属性对应当前上下文的名字。
spring中变量的使用
如果要使用spring中定义的变量,logback的配置文件要以logback-spring.xml命名,其他如property需要修改为springProperty。示例:
1 | <configuration> |
https://juejin.im/post/5b51f85c5188251af91a7525
https://logbackcn.gitbook.io/logback
https://juejin.im/post/5d4d61326fb9a06aff5e5ff5
https://juejin.im/post/5d66a36c518825199701e2ad
https://zhuanlan.zhihu.com/p/36554554

