日常编程中,对ConcurrentSkipListMap使用得比较少,因此对它的了解程度也不足,趁着今天复习容器的机会学习一下ConcurrentSkipListMap。
JDK的容器中Map对应的有HashMap、TreeMap、ConcurrentHashMap、ConcurrentSkipListMap等。其中HashMap是基于哈希的容器,插入与查找性能为O(1);TreeMap是基于红黑树的容器,其中的元素有有序的,插入与查找性能为O(logN);ConcurrentHashMap是线程安全的HashMap;ConcurrentSkipListMap也是线程安全的,插入与查找性能为O(logN),其基于skip list数据结构,有着不低于红黑树的效率,但是其原理和实现的复杂度要比红黑树简单。
跳表
跳表(skip list)是一种对标平衡树的数据结构,插入/删除/搜索操作性能都是O(logN)。其最大的优势是原理简单、容易实现、方便扩展、效率更高。
假设有如下一个有序的链表:

这个链表中,如果要搜索一个数,需要从头到尾比较每个元素是否匹配,直到找到匹配的数为止,即时间复杂度为O(n)。同理,插入一个数并保持链表有序,需要先找到合适的插入位置,在执行插入,总计也是O(n)的时间。
为了提高性能,我们需要对链表加上索引:

如上图,在链表的上层加了索引层,它包含的元素为前一个链表的偶数个元素。这样在搜索一个元素时,我们先在索引层进行搜索,当元素未找到时再到下层链表中搜索。例如搜索数据19时的路径如下:

先在上层中搜索,到达节点17时发现下一个节点为21,已经大于19,于是转到下一层搜索,找到目标数字19。
我们知道上层的节点数目为n/2,因此,有了这层索引,我们搜索的时间复杂度降为了O(n/2)。同理,我们可以不断地增加层数,来减少搜索的时间:
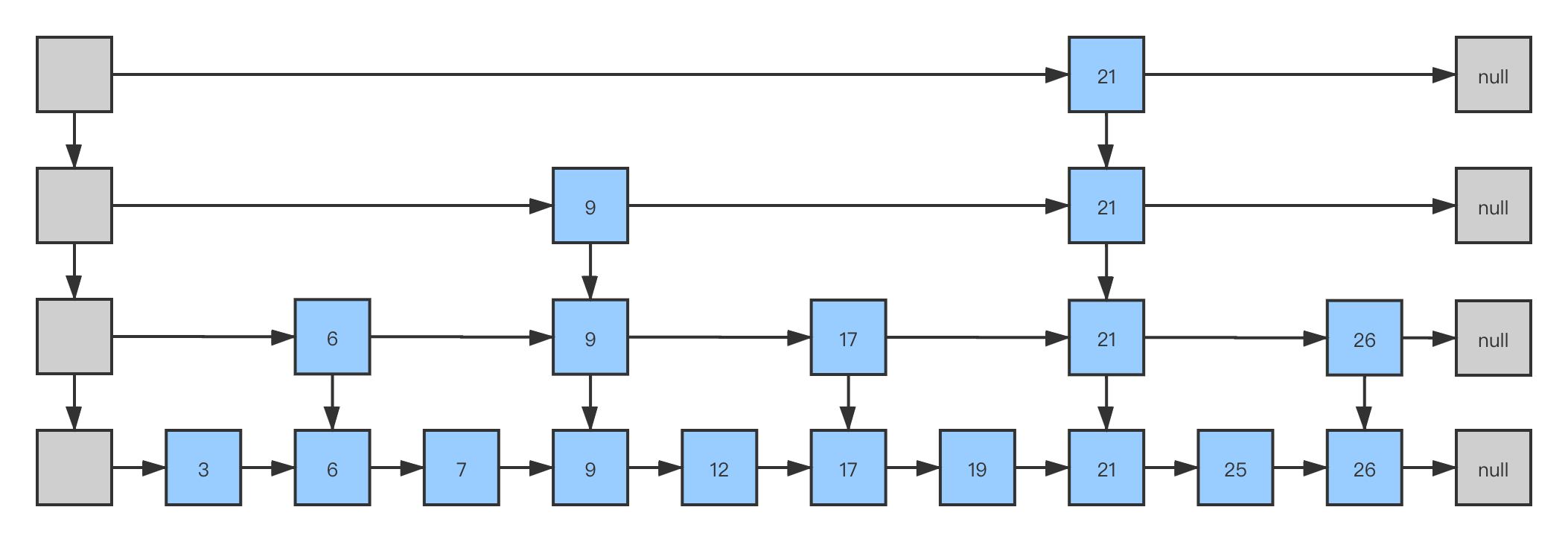
在上面的4层链表中搜索25,在最上层搜索时就可以直接跳过21之前的所有节点,因此十分高效。
上面的结构是”静态”的,即我们先拥有了一个链表,再在之上建了多层的索引。但是在实际使用中,我们的链表是通过多次插入/删除形成的,换句话说是”动态”的。上面的结构要求上层相邻节点与对应下层节点间的个数比是1:2,随意插入/删除一个节点,这个要求就被破坏了。
因此跳表(skip list)表示,我们不强制要求1:2,一个节点要不要被索引,建几层的索引,都在节点插入时由抛硬币决定。当然,虽然索引的节点、索引的层数是随机的,为了保证搜索的效率,要大致保证每层的节点数目与上面的结构相当。
ConcurrentSkipListMap
ConcurrentSkipListMap采用的就是跳表的数据结构,它提供了3个内部类来构建这样的数据结构:Node、Index、HeadIndex。
Node表示最底层的单链表有序节点:
1 | static final class Node<K,V> { |
Node的结构就是一个单链表的节点,包含一个key、一个value、一个指向下一个节点的next。
Index表示基于Node的索引层:
1 | static class Index<K,V> { |
Index包含链表的节点Node,以及一个指向下一个Index的right、一个指向下层索引的down。
HeadIndex用来维护索引层次:
1 | static final class HeadIndex<K,V> extends Index<K,V> { |
HeadIndex扩展了Index,增加了一个level变量来定义层级。
还有一个head变量来表示最上层的HeadIndex:
1 | private transient volatile HeadIndex<K,V> head; |
put方法
put方法代码如下:
1 | public V put(K key, V value) { |
首先判断value不为null,接着调用doPut方法。doPut方法分为3个部分。
第一部分
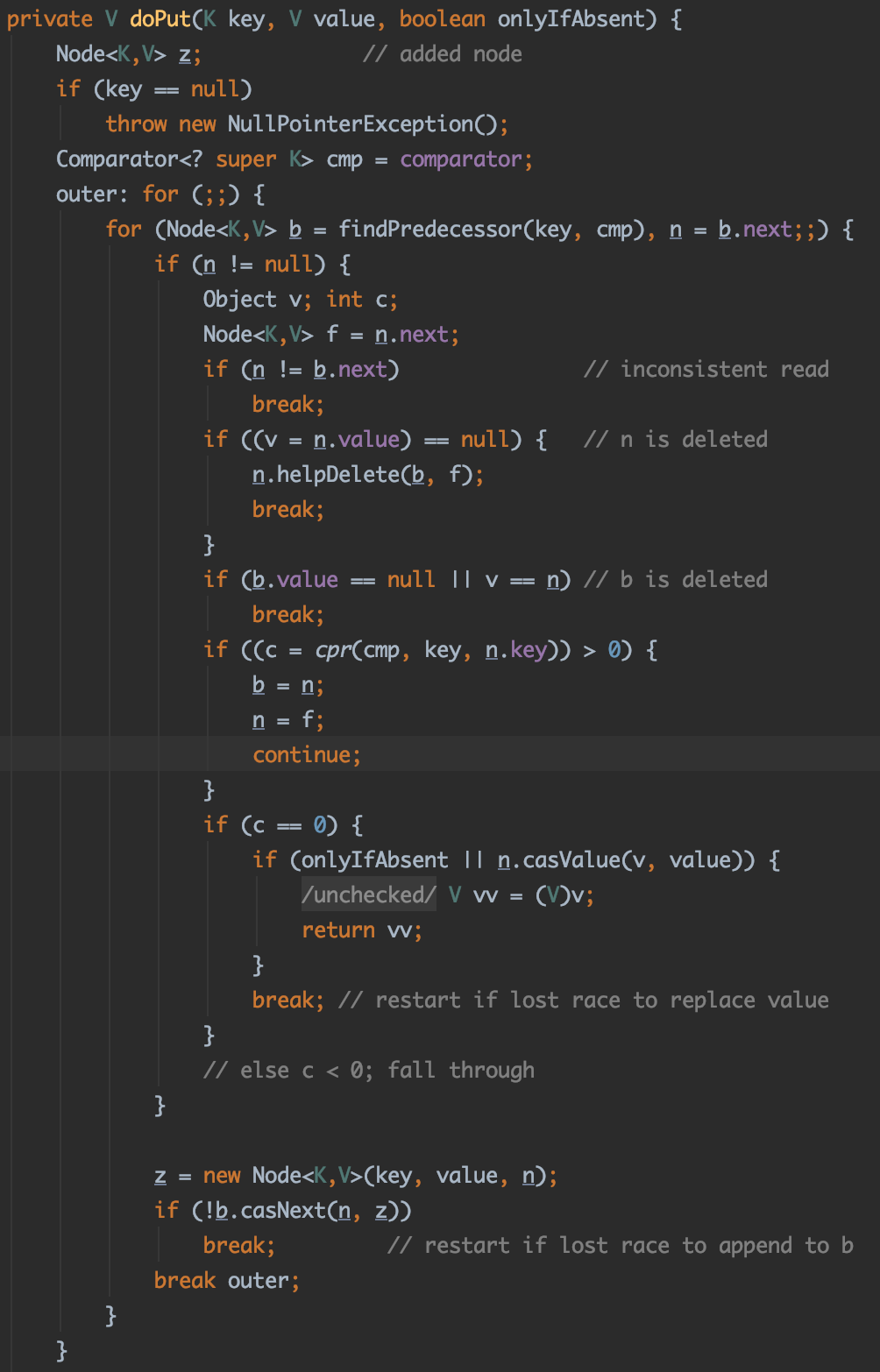
第一部分要做的是将数据插入到最底层的链表中。主要的步骤就是找到数据该插入的前置节点,使用传入的数据建立一个新节点,将新节点插入到前置节点的后面。
ConcurrentSkipListMap使用cas无锁的方式来保证并发情况下的线程安全性,因此这些操作都是在一个大循环中执行的,检测到数据有并发修改时从循环的开头重新执行。jdk的并发容器中很多类都采用这样的方式来保证线程安全性。为了理解的方便,我们可以忽略这些代码,专注于主要的操作流程。
首先调用findPredecessor方法找到key插入的前置节点,代码如下:
1 | private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) { |
步骤如下:
- 从
head位置开始遍历,q指向当前节点,r指向当前节点右边的(下一个)节点。 - 如果
r指向的节点value为null,表示该节点已经被删除了,通过调用unlink()方法删除该节点。 - 调用
cpr比较r节点与当前key的大小,直到当前key小于r节点。这一层的遍历就已经完成了 - 接着向下走一层。如果已经走到最下层,直接返回该节点。否则在这一层重复遍历的过程,直到走到最下层。
findPredecessor方法结束之后返回插入位置的前置节点,回到doPut方法,b指向该前置节点,n指向前置节点的后置节点:
- 比较插入的
key与后置节点的key,如果相等则需要进一步判断:如果传入的onlyIfAbsent参数为false则替换后置节点的value值,并返回原来的value值;否则不做替换,直接返回原来的value值。 - 根据传入的
key和value参数新建一个Node节点,它的next指向原来的后置节点(n)。 - 前置节点(
b)的next指向该新插入的节点。
至此,新节点已经插入到合适的位置了。
第二部分
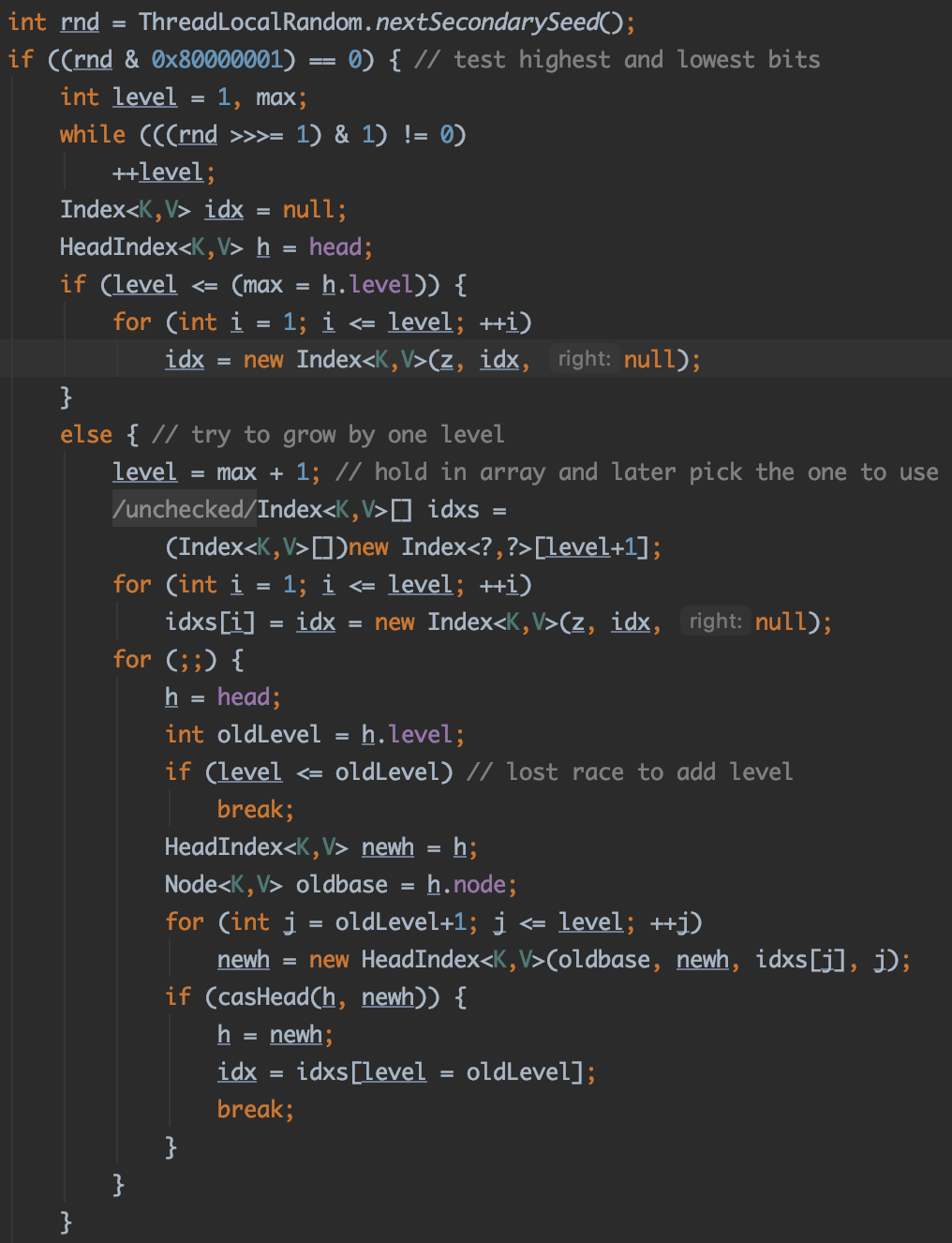
在新节点插入完成后,下一步的工作就是为这个节点新建索引。前面我们说过,采用抛硬币的方式来决定新节点搜索的层次。
第一步,使用ThreadLocalRandom.nextSecondarySeed()来生成随机数,通过if ((rnd & 0x80000001) == 0)来判断最高位和最低位,只有随机数的最高位和最低位都不为1(即正偶数)才执行后面的操作
第二部,通过下面的代码来得到索引的层数:
1 | int level = 1, max; |
从随机数最低位的第二位开始计算,有几个连续的1则level加几。比如1100110,level就加2。注意这里的level初始值为1,也就是代码执行到这里就至少会建立一层索引。
确定了level之后,根据level与当前最高层次的比较执行不同的操作。
如果level小于或等于当前的最高层次:从最底层开始,每一层都初始化一个Index,每个Index都指向刚刚新加入的Node,down指向下一层的Index,right全部指向null。
如果level大于当前的最高层次:
level在当前最高层次的基础上加1- 新建
level+1个Index,每个Index都指向刚刚新加入的Node,down指向下一层的Index,right全部指向null。 - 为新增的层次新建
HeadIndex,down指向原先的HeadIndex,right指向上一步骤新增的Index - 通过CAS将
head指向新的HeadIndex
至此,我们为新增的节点确定了层次并生成了相应的Index,但是这些Index还没有插入到相应的层次中。所以第三部分就是将Index插入到相对应的层次中。
第三部分
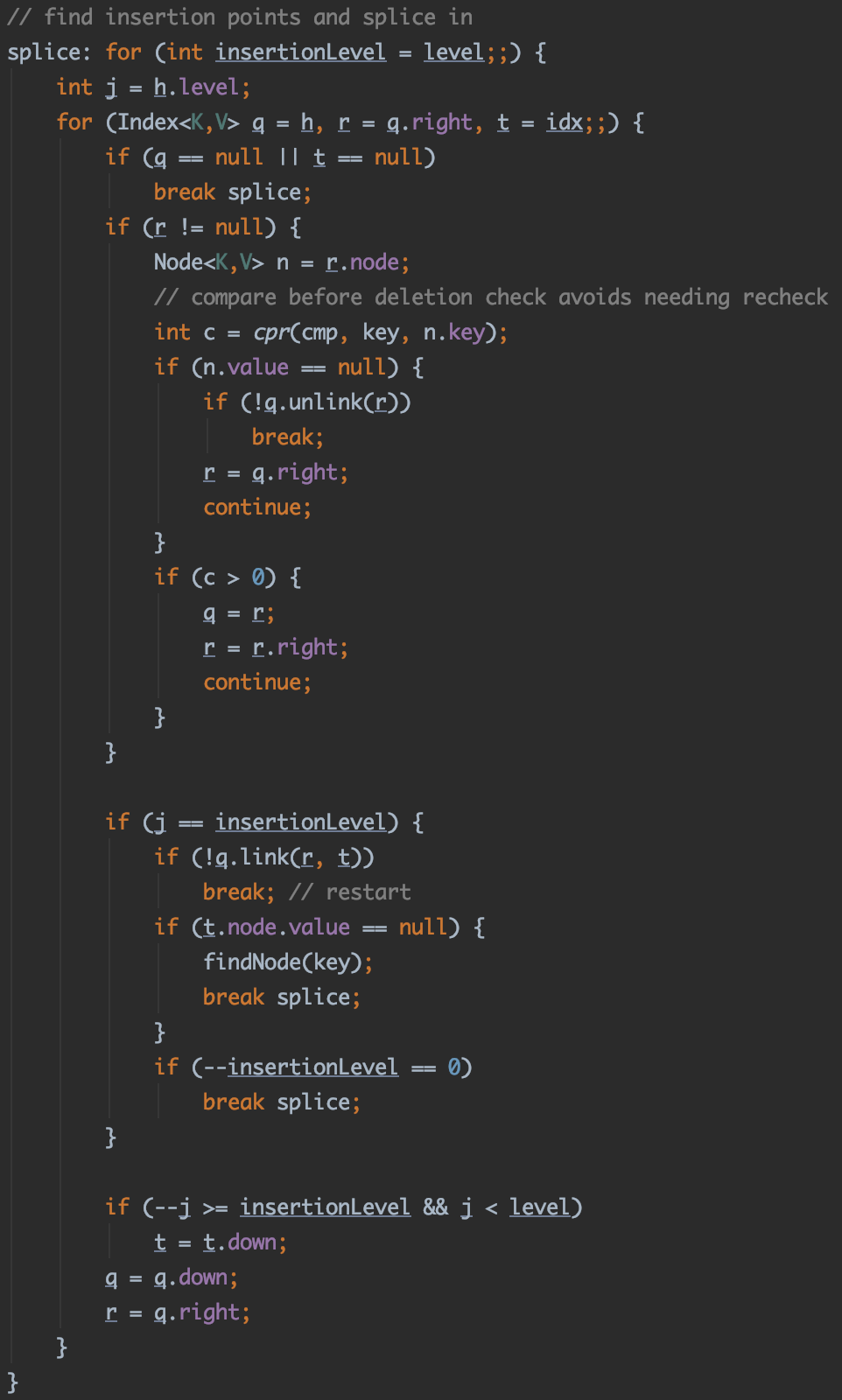
- 从上到下遍历,首先通过
key与节点的比较找到插入的位置 - 如果当前层次是
Index所在的层次,则通过link()方法将新的Index关联到这一层 - 然后下移一层,继续关联新加入的
Index
至此,doPut方法就结束了,总结一下,它主要分为3个步骤:
- 通过
findPredecessor方法找到插入位置的前置节点,根据传入的key和value新建节点,然后在前置节点后插入新建的节点 - 根据抛硬币的方式决定插入节点索引的层次,根据层次新建索引
Index - 最后将新增的
Index插入到整个skip list结构中
get方法
相比于put()方法,get()方法简单很多,其过程就只相当于put()方法的第一步
- 调用
findPredecessor()方法找到前置节点 - 然后顺着
next一直往下寻找,直到找到并返回相同key的节点,或者返回null
remove方法
remove方法为删除指定key的节点,其直接调用doRemove方法:
1 | public V remove(Object key) { |
可以看到doRemove方法有两个参数,一个是key,另一个是value,所以doRemove可以保证节点中的key和value同时和传入的数据相等时才删除元素。
不过remove方法传入的value为null,即只需要找到对应的key删除即可。
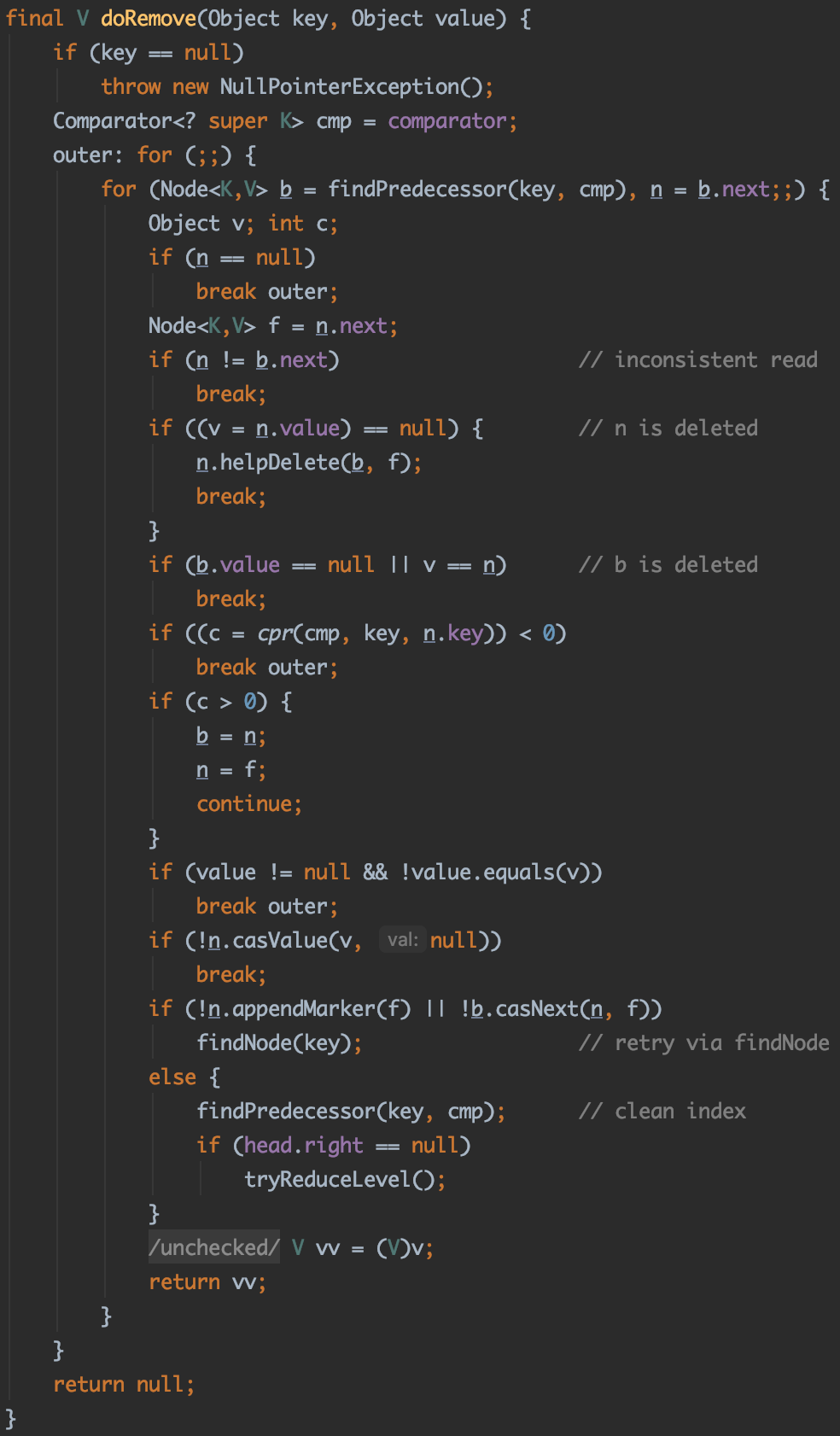
步骤如下:
- 调用
findPredecessor方法找到前置节点b,n为前置节点的下一个节点,f为下下个节点 - 调用
cpr方法比较节点的key值,遍历链表,找到需要删除的节点 - 如果
value不为空且不等于找到元素的value,不需要删除,退出外层循环 - 通过CAS将待删除节点
n的value设置为null 删除
n节点:- 第一步调用
n.appendMarker(f)将n节点标记为可以被删除,如果标记成功再执行第二步b.casNext(n, f)将b的下个节点指向下下个节点。 - 如果第一步执行失败或者第二步执行失败,调用
findNode()重试删除 - 只有第一步和第二部都执行成功,才会进入
else方法块。代码走到这里说明节点已经成功删除了,于是调用findPredecessor方法删除节点的索引。head.right == null判断最高层的头索引节点没有右节点,说明这一层没有索引节点了,于是调用tryReduceLevel降低跳表的高度。
- 第一步调用
size方法
ConcurrentSkipListMap的size()方法并没有维护一个全局的变量来统计元素的个数,而是每次调用方法时去遍历统计元素的个数:
1 | public int size() { |
调用findFirst()方法找到链表的第一个节点,然后向后遍历链表统计链表中元素的个数。
https://juejin.im/post/5d9beab85188251d805f3f6c
https://lotabout.me/2018/skip-list/
https://zhuanlan.zhihu.com/p/53975333
https://segmentfault.com/a/1190000020601226
https://juejin.im/post/5cdc38236fb9a0322d04ac7b
https://juejin.im/post/57fa935b0e3dd90057c50fbc
https://zhuanlan.zhihu.com/p/33674267

