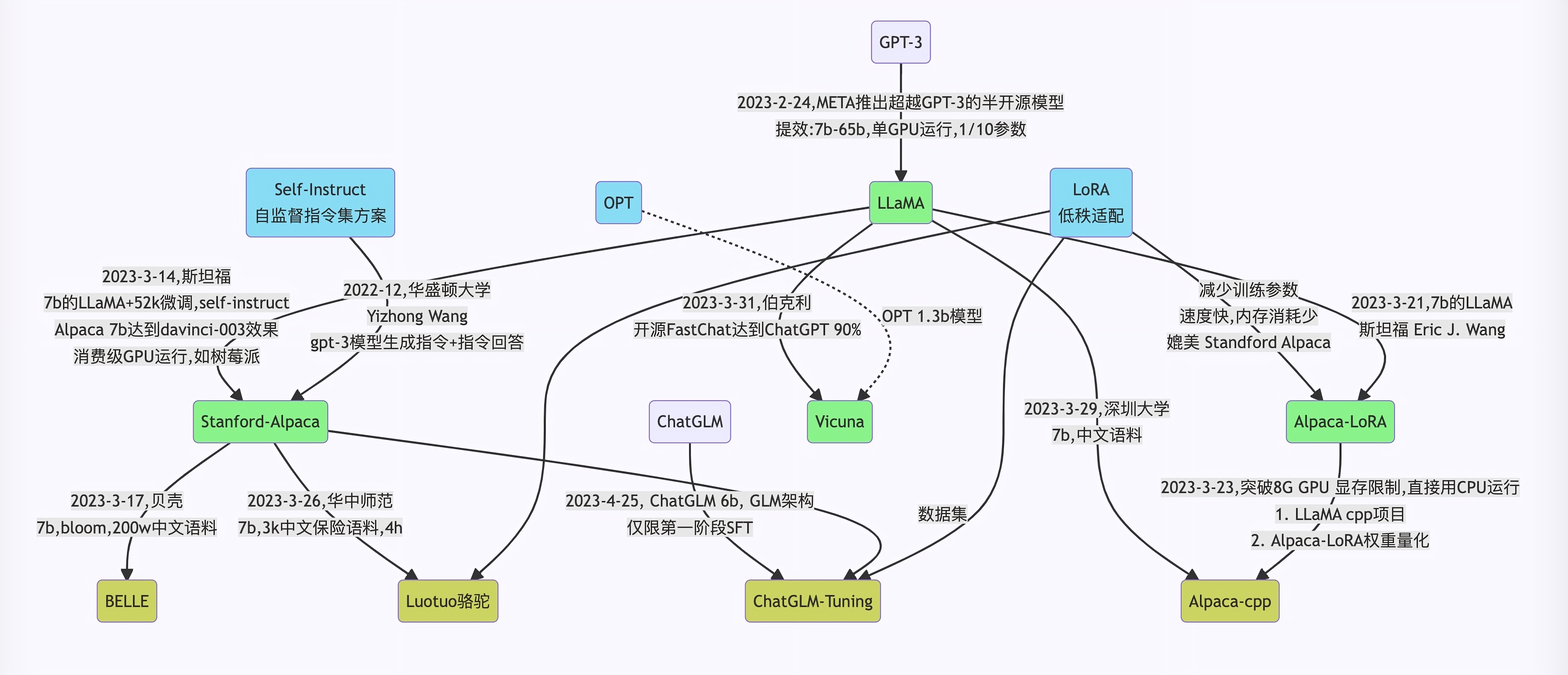
随着ChatGPT的火爆,大语言模型领域又开始热闹起来。不过GPT-3.5和GPT-4并没有开源,随着Meta开源了LLaMA模型,相关的开源模型逐渐开始走进人们视野。
LLaMA
Meta“泄露”的大语言模型。magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA
llama cpp
用于LLaMA模型推理的纯C++版本,可以在CPU环境下运行LLaMA模型。包括LLaMA以及Alpaca等衍生的模型。
https://github.com/ggerganov/llama.cpp
编译
clone代码:
1 | git clone https://github.com/ggerganov/llama.cpp |
使用make来编译:
1 | make |
或者使用cmake来编译:
1 | mkdir build |
BLAS编译使用
编译时支持BLAS
OpenBLAS
使用make:
1 | make LLAMA_OPENBLAS=1 |
使用cmake:
1 | mkdir build |
cuBLAS
cuBLAS使用CUDA来加速算法。
使用make:
1 | make LLAMA_CUBLAS=1 |
使用cmake:
1 | mkdir build |
使用GPU,需要在运行时加上-ngl参数,指定多少layer保存在GPU上
运行llama模型
准备数据并运行
1 | # obtain the original LLaMA model weights and place them in ./models |
推理的典型用法:
1 | ./main -m ./models/7B/ggml-model-q4_0.bin -p "Building a website can be done in 10 simple steps:" -n 512 |
alpaca
Alpaca是在LLaMA上进行微调的。而为了训练这个语言模型,科学家们使用OpenAI的 “text-davinci-003 “模型,生成了52K高质量的自我指导数据。有了这个数据集,他们使用HuggingFace的训练框架对LLaMA模型进行了微调。
https://github.com/tatsu-lab/stanford_alpaca
运行
可以使用llama.cpp来运行。下载ggml的Alpaca模型,放到./models目录。接着执行:
1 | ./examples/alpaca.sh |
alpaca-lora
在消费级GPU上微调“基于LLaMA的Alpaca”。
https://github.com/tloen/alpaca-lora
Chinese-LLaMA-Alpaca
Chinese LLaMA(也称中文LLaMA,有7B和13B两个版本),相当于在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力,同时,在中文LLaMA的基础上,且用中文指令数据进行指令精调得Chinese-Alpaca(也称中文Alpaca,同样也有7B和13B两个版本)
https://github.com/ymcui/Chinese-LLaMA-Alpaca
运行
下载中文模型。
手动模型合并与转换
手动模型合并与转换 · ymcui/Chinese-LLaMA-Alpaca Wiki (github.com)
将原版LLaMA模型转换为HF格式
请使用🤗transformers提供的脚本convert_llama_weights_to_hf.py,将原版LLaMA模型转换为HuggingFace格式。
1 | python src/transformers/models/llama/convert_llama_weights_to_hf.py \ |
合并LoRA权重,生成模型权重
这一步骤会对原版LLaMA模型(HF格式)扩充中文词表,合并LoRA权重并生成全量模型权重。此处可以选择输出PyTorch版本权重(
.pth文件)或者输出HuggingFace版本权重(.bin文件)。.pth文件可用于:
1 | python scripts/merge_llama_with_chinese_lora.py \ |
llama.cpp量化部署
llama.cpp量化部署 · ymcui/Chinese-LLaMA-Alpaca Wiki (github.com)
- 生成量化版本的模型
1 | # 将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin。 |
- 加载并启动模型
1 | ./main -m zh-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1 |
BELLE
BELLE是链家推出的模型,也是对LLaMA的微调。
https://github.com/LianjiaTech/BELLE
ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
https://github.com/THUDM/ChatGLM-6B
模型地址:
https://huggingface.co/THUDM/chatglm-6b
模型推理
- clone代码
1 | git clone https://github.com/THUDM/ChatGLM-6B.git |
- 使用pip安装依赖:
1 | pip install -r requirements.txt |
- clone模型
1 | git clone https://huggingface.co/THUDM/chatglm-6b |
运行程序demo
有3种方式来运行程序:
- 命令行方式
1 | python cli_demo.py |
2. 网页方式1
1 | python web_demo.py |
3. 网页方式2
1 | streamlit run web_demo2.py |
GLM-130B
GLM-130B是一个具有1300亿个参数的大模型。支持中英双语,性能出众。
https://github.com/THUDM/GLM-130B
但是硬件要求较高,没有部署测试
| Hardware | GPU Memory | Quantization | Weight Offload |
|---|---|---|---|
| 8 * A100 | 40 GB | No | No |
| 8 * V100 | 32 GB | No | Yes (BMInf) |
| 8 * V100 | 32 GB | INT8 | No |
| 8 * RTX 3090 | 24 GB | INT8 | No |
| 4 * RTX 3090 | 24 GB | INT4 | No |
| 8 * RTX 2080 Ti | 11 GB | INT4 | No |
RWKV
RWKV根据新的深度学习模型架构,以循环神经网络RNN为基础魔改而来。
https://github.com/BlinkDL/RWKV-LM
模型地址:
https://huggingface.co/BlinkDL/rwkv-4-raven
运行
1 | # 克隆ChatRWKV项目 |

