当数据量比较小的情况下,我们可以直接将其插入单台机器的一个索引中,es的性能足够应付。当数据量变得比较大,我们可以将es的索引分片,将分片分配到不同的机器上,并行搜索以满足性能的要求。当插入海量数据到es的索引中时,一个分片中的数据变得很大,此时搜索性能就会下降,因为成本的考虑,我们不能再随意横向扩容。这个时候我们就需要新的思路来解决这个问题。
所幸的是,在绝大多数的场景下,数据都是具有时间局部性的,时间近的数据往往访问频繁(即热数据),时间远的数据往往访问较少(即冷数据)。根据这个特性,我们可以将数据拆分到不同的索引中,热数据索引可以设置较多的分片,分配到性能较高的机器上。冷数据索引设置较少的分片以节约存储空间,分配到性能普通的机器上。这样可以在确保绝大多数访问性能的情况下,最大限度地节约成本。
本文是我对冷热数据分离方案的学习与总结。
下面我们先来看看es为我们提供了怎样便利的工具来实现冷热数据分离的目标
rollover
通常情况下,我们会以索引数据的时间、索引文档数据、索引大小来拆分索引。为了做这样的拆分,我们可以在程序中去监控索引的这三个指标,在必要的时候(超过了一定的时间、,索引中文档数过多,索引太大)新建一个索引,然后将新数据插入到新建的索引。
不过,es已经为我们提供了这样的功能,叫做rollover。
rollover判断别名所对应的索引,当索引满足了我们设置的条件时,新建一个索引。rollover可以判断的条件有以下3个:
max_age:索引中最早插入数据距今的时间max_docs:索引中最大的文档数max_size:索引最大的大小
示例:
首先创建一个名为logs-000001的索引,别名设置为logs_write:
1 | curl -X "PUT" "http://10.0.20.33:9200/logs-000001" \ |
在logs-000001插入一些数据。然后调用rollover:
1 | curl -X "POST" "http://10.0.20.33:9200/logs_write/_rollover" \ |
可以看到,我们在rollover中设置了3个条件,分别表示索引中最多容纳7天的数据,或者1条文档,或者5db大小的数据。根据返回值我们知道max_docs条件生效了,因此rollover新建了一个新的索引logs-000002。
查看别名logs_write:
1 | curl "http://10.0.20.33:9200/_alias/logs_write" |
我们看到,别名logs_write指向了新的索引logs-000002。这样我们在程序中就可以无感知地将数据通过别名logs_write插入到新的索引logs-000002中。
以日期命名的索引
我们还可以用一下命令创建一个以日期命名的索引:
1 | curl -X "PUT" "http://10.0.20.33:9200/%3Clogs-%7Bnow%2Fd%7D-000001%3E" \ |
可以看到,上述命令新建了一个名为logs-2019.07.15-000001的索引。
在logs-2019.07.15-000001插入一些数据。然后调用rollover:
1 | curl -X "POST" "http://10.0.20.33:9200/logs_date_write/_rollover" \ |
根据返回值我们知道max_docs条件生效了,因此rollover新建了一个新的索引logs-2019.07.15-000002。
查看别名logs_date_write:
1 | curl "http://10.0.20.33:9200/_alias/logs_date_write" |
我们看到,别名logs_date_write指向了新的索引logs-2019.07.15-000002。
index templates
通过前面的rollover,我们已经可以做到在满足条件时新建索引,并将别名指向新的索引。在实际场景下这个功能还有所欠缺,因为rollover不会复制原来索引的settings和mappings,因此新的索引不满足我们的使用要求。
此时,我们需要引入index templates,索引模板。
index templates可以为指定样式的一类索引定义模板,当满足样式的索引新建时,会自动应用模板中定义的settings和mappings。
还以上面的日志为例,我们可以为所有日志相关的索引建立一个模板:
1 | curl -X "PUT" "http://10.0.20.33:9200/_template/logs-template" \ |
可以看到,这个模板匹配所有以logs-开头的索引,在模板中设置了mappings、settings。
接下来重复上面的步骤。
新建索引:
1 | curl -X "PUT" "http://10.0.20.33:9200/%3Clogs-%7Bnow%2Fd%7D-000001%3E" \ |
查看索引:
1 | curl "http://10.0.20.33:9200/%3Clogs-%7Bnow%2Fd%7D-000001%3E" |
可以看到,新建的索引是按我们的模板来配置的。
在logs-2019.07.15-000001插入一些数据。然后调用rollover:
1 | curl -X "POST" "http://10.0.20.33:9200/logs_date_write/_rollover" \ |
可以看到,经过调用rollover,新建了一个logs-2019.07.15-000002索引。查看logs-2019.07.15-000002索引的信息:
1 | curl "http://10.0.20.33:9200/logs-2019.07.15-000002" |
新的索引也应用了模板中的设置。
冷热数据分离实践
有了上面rollover和index templates的铺垫,我们可以正式进行冷热数据分离的实践。
首先准备了3个节点(node-1、node-2、node-3)来模拟正式环境下的集群环境。
首先为热数据新建索引模板:
1 | curl -X "PUT" "http://10.0.20.33:9200/_template/hot-logs-template" \ |
接着创建索引hot-logs-1:
1 | curl -X "PUT" "http://10.0.20.33:9200/hot-logs-1" \ |
插入数据并调用rollover:
1 | curl -X "POST" "http://10.0.20.33:9200/hot-logs/_rollover" \ |
max_docs条件生效,新建了一个索引hot-logs-000002。
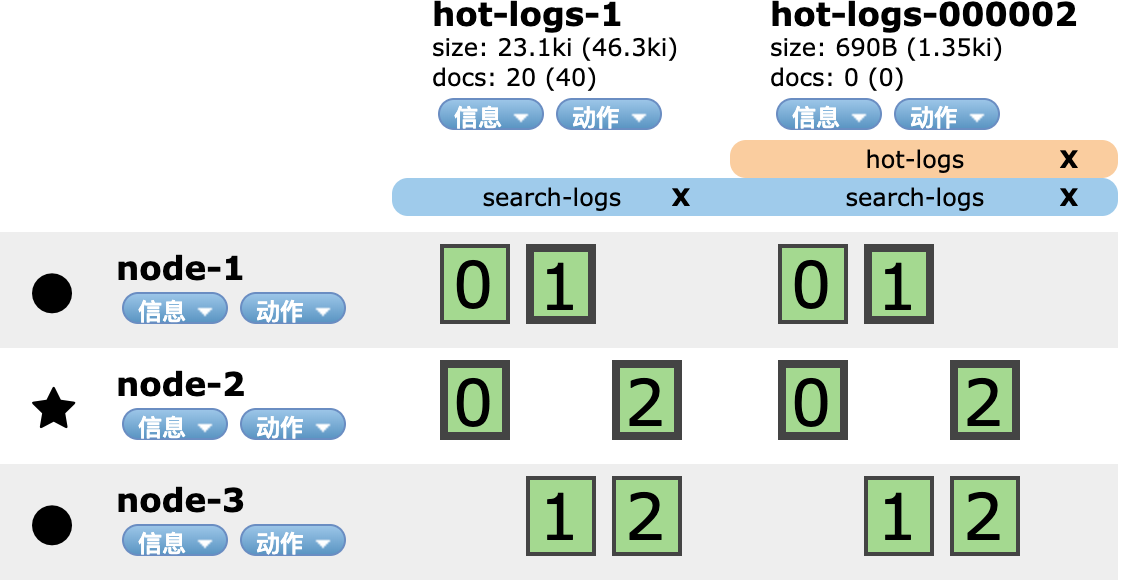
此时,别名search-logs指向hot-logs-1和hot-logs-000002两个索引,别名hot-logs指向新的hot-logs-000002索引。这样,我们就可以使用hot-logs别名来插入数据,使用search-logs来在多个索引上搜索数据。
压缩数据
经过上面的操作,可以根据不同的条件可以不断的新建索引,将新的数据插入到新的索引中。我们还可以对老的索引进行压缩来节约空间。
首先新建一个冷数据索引的模板:
1 | curl -X "PUT" "http://10.0.20.33:9200/_template/cold-logs-template" \ |
将分片设为1,副本设为0
接下来,我们可以使用shrink来压缩hot-logs-1索引。
首先,将hot-logs-1索引所有的分片都复制到一个节点上,并将该索引设置为只读:
1 | curl -X "PUT" "http://10.0.20.33:9200/hot-logs-1/_settings" \ |
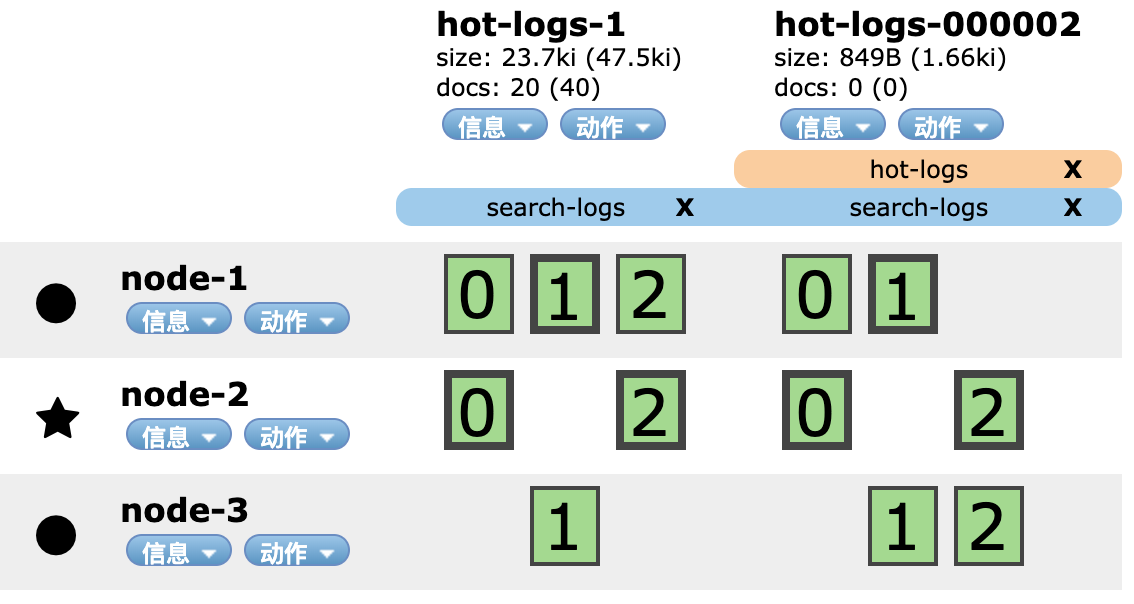
经过上面的步骤,hot-logs-1索引的0、1、2三个分片都被复制到node-1节点上。
然后我们就可以对hot-logs-1索引执行shrink操作:
1 | curl -X "POST" "http://10.0.20.33:9200/hot-logs-1/_shrink/cold-logs-1" |
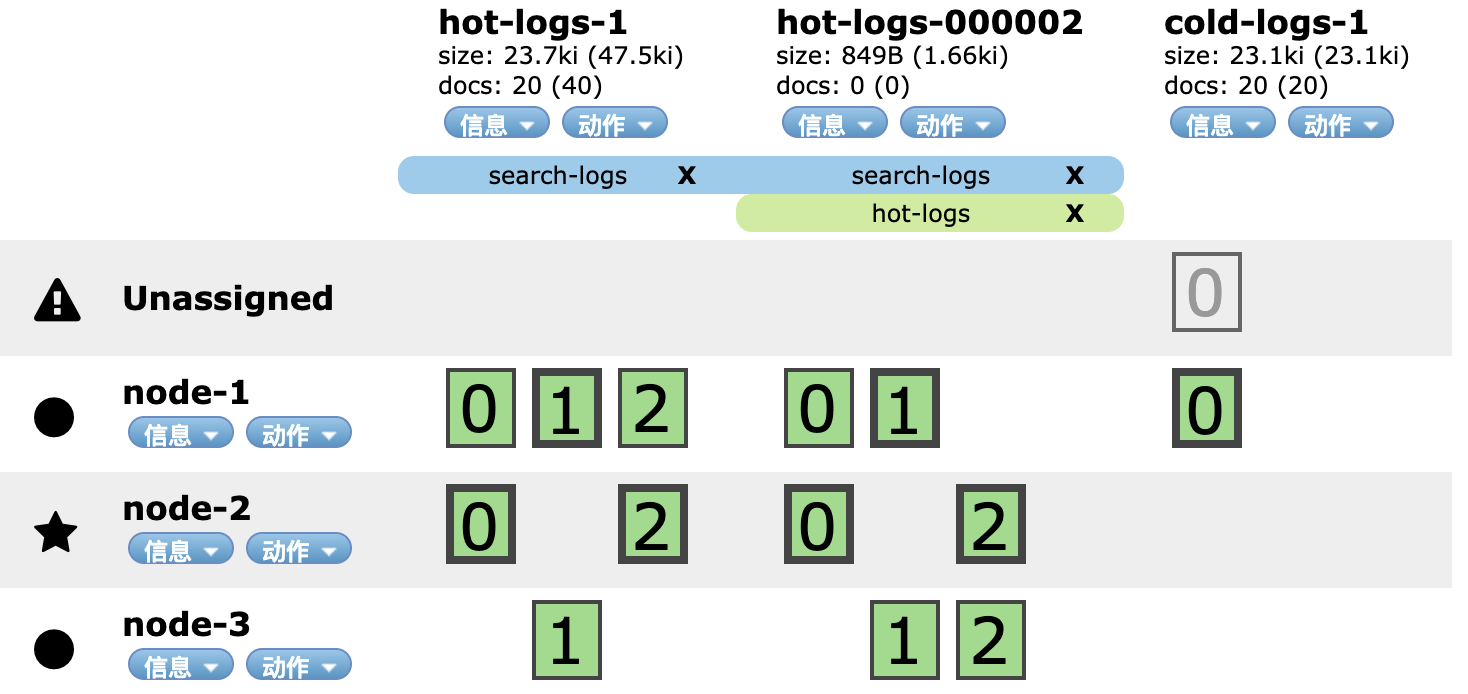
执行完之后,cold-logs-1只剩下一个分片
因为索引hot-logs-1被压缩成了cold-logs-1,因此我们需要调整别名search-logs。删除指向hot-logs-1,增加指向cold-logs-1。
1 | curl -X "POST" "http://10.0.20.33:9200/_aliases" \ |
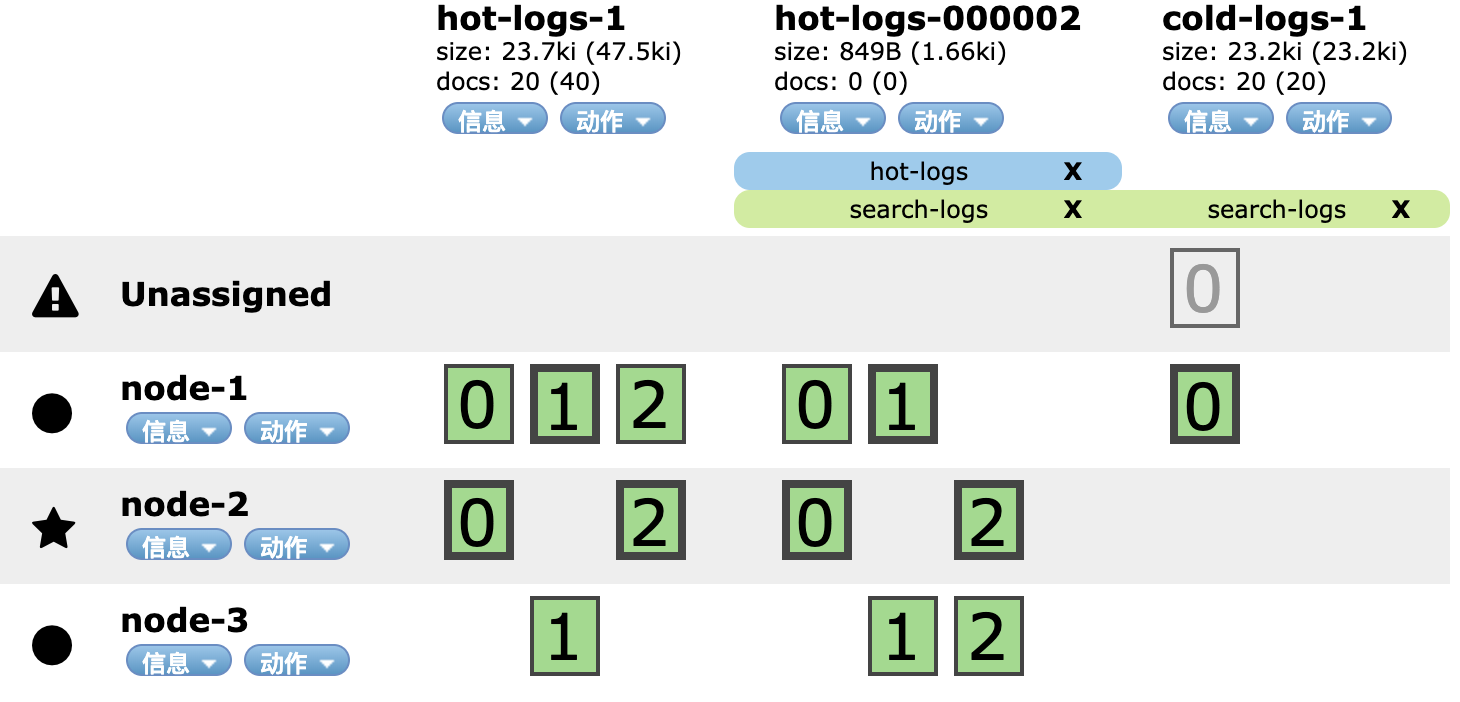
随后,我们可以强行合并索引中的segment来减少空间的使用:
1 | curl -X "POST" "http://10.0.20.33:9200/cold-logs-1/_forcemerge?max_num_segments=1" |
在主分片和副本上同时合并数据没有意义,所以我们之前将number_of_replicas设置为0。强制合并完成后,我们可以增加副本数量以获得冗余。
1 | curl -X "PUT" "http://10.0.20.33:9200/cold-logs-1/_settings" \ |
最后彻底删除hot-logs-1索引:
1 | curl -X "DELETE" "http://10.0.20.33:9200/hot-logs-1" |
Index Lifecycle Management
上面我们进行了冷热数据分离的实践。我们看到,虽然步骤并不多,但是依然需要我们定时调用rollover来检查并新建索引,调用shrink来压缩数据。
这依然是一个比较繁琐的操作,那么有没有自动监控索引,并执行rollover、shrink操作的工具呢?答案是有的。
比如Curator,又比如Index Lifecycle Management。Index Lifecycle Management是Elasticsearch 6.6版本以后提供的功能,用于控制一个索引的生命周期。
Index Lifecycle Management为一个索引的生命周期抽象了4个阶段,他们分别代表了数据的4种状态:
hot:正在有大量的数据被写入warm:通常不会被写入数据,但仍然会被查询cold:索引不再更新,也很少被查询。但是仍然需要搜索,不过即使查询速度较慢也没关系。delete:索引可以被安全地删除
假设有这样的场景:
- 时间每过1分钟或者数据量达到了1G,则新建一个索引
- 时间每过5分钟,对数据进行压缩清理,保留一个分片
- 时间每过10分钟,对数据再次进行清理,保留一个副本
- 时间每过20分钟,将索引直接删除
针对这样的场景,我们在Index Lifecycle Management中新建一个策略(policy),如下所示:
1 | curl -X "PUT" "http://10.0.20.33:9200/_ilm/policy/log_policy" \ |
接着我们将这个policy关联到索引模板中:
1 | curl -X "PUT" "http://10.0.20.33:9200/_template/logs-template" \ |
可以看到,原始的索引拥有3个分片以及3个副本。通过index.lifecycle.name来配置关联的policy,这意味着所有匹配logs-*的索引都会被log_policy管理。最重要的一个设置是index.lifecycle.rollover_alias,如果我们要使用rollover操作就必须要设置这个参数,它指定了rollover在哪个别名上操作。
最后新建第一个索引logs-000001:
1 | curl -X "PUT" "http://10.0.20.33:9200/logs-000001" \ |
注意,ILM Service会在后台轮询执行policy,默认间隔时间为10分钟。为了能更快看到效果,我们将其修改为1秒。
1 | curl -X "PUT" "http://10.0.20.33:9200/_cluster/settings" \ |
经过上面的设置,我们可以不管冷热数据分离的具体操作,直接往logs_write中写入数据即可。es会自动对我们的索引执行rollover、shrink、merge等等操作。
https://www.elastic.co/cn/blog/managing-time-based-indices-efficiently
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-index-lifecycle-management.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/indices-rollover-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-templates.html

