ConcurrentHashMap的实现在JDK1.7和JDK1.8中有着很大的区别。
在JDK1.7中,ConcurrentHashMap采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构。
其包含两个核心静态内部类Segment和HashEntry。
- Segment继承ReentrantLock用来充当锁的角色,每个Segment对象守护每个散列映射表的若干个桶
- HashEntry用来封装映射表的键/值对
- 每个桶是由若干个HashEntry对象链接起来的链表
JDK1.8中,ConcurrentHashMap抛弃了Segment分段锁机制,取而代之的是采用Node + CAS + Synchronized来保证并发安全地进行。对于锁的粒度,调整为对每个数组元素加锁(Node)。
本文根据JDK1.8来研究ConcurrentHashMap的实现。
相关属性
private transient volatile int sizeCtlsizeCtl用于控制table[]的初始化与扩容操作,不同值代表不同状态:
- -1:table[]正在初始化
- -N:表示有N-1个线程正在进行扩容操作
- 非负情况:
- 如果table[]未初始化,则表示table需要初始化的大小
- 如果初始化完成,则表示table[]扩容的阈值,默认是table[]容量的0.75倍
private static final int DEFAULT_CAPACITY = 16table默认的初始大小
private static final float LOAD_FACTOR = 0.75f默认的负载因子
static final int TREEIFY_THRESHOLD = 8链表转红黑树的阈值,当table[i]下面的链表长度大于8时就转化为红黑树结构
static final int UNTREEIFY_THRESHOLD = 6红黑树转链表的阈值,当链表长度<=6时转为链表
static final int MIN_TREEIFY_CAPACITY = 64链表转红黑树要满足的最少table容量,否则table会选择扩容。这个值必须至少是4 * TREEIFY_THRESHOLD,避免扩容和转红黑树之间出现冲突。
相关节点
- Node:该类用于构造table[],只读节点(不提供修改方法)
- TreeBin:红黑树结构
- TreeNode:红黑树节点
- ForwardingNode:临时节点(扩容时使用)
put方法
1 | public V put(K key, V value) { |
put方法对当前的table一直循环直到put成功,可以分为一下几个步骤:
- 如果没有初始化就先调用initTable()方法来初始化table
- 如果没有hash冲突就使用CAS方法插入
- 如果正在进行扩容就参与扩容
- 如果存在hash冲突,就在头节点上加锁,如果是链表形式就直接遍历到末尾然后插入,如果是红黑树形式就插入到红黑树中
- 判断链表中节点数量是否大于阈值8,如果是则转换成红黑树结构
- 添加成功后调用addCount()方法统计size,并且检查是否需要扩容
initTable方法
1 | private final Node<K, V>[] initTable() { |
helpTransfer方法
1 | final Node<K, V> helpTransfer(Node<K, V>[] tab, Node<K, V> f) { |
helpTransfer()方法的目的就是调用多个工作线程一起帮助进行扩容,这样的效率会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作。
transfer方法
1 | private final void transfer(Node<K, V>[] tab, Node<K, V>[] nextTab) { |
ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历。
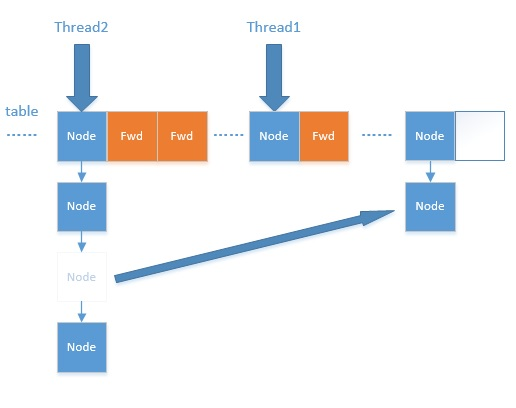
treeifyBin方法
1 | private final void treeifyBin(Node<K, V>[] tab, int index) { |
tryPresize方法
1 | private final void tryPresize(int size) { |
addCount方法
1 | private final void addCount(long x, int check) { |
计数的逻辑参考了java.util.concurrent.atomic.LongAdder。它的作者也是Doug Lea。核心思想是在并发较低时,只需更新base值。在高并发的情况下,将对单一值的更新转化为数组上元素的更新,以降低并发争用。总的映射个数为base + CounterCell各个元素的和。如果总数大于阈值,扩容。
可以发现,ConcurrentHashMap在并发处理中使用的是乐观锁,当有冲突的时候才进行并发处理,而且流程步骤很清晰,但是细节设计很复杂。
get方法
1 | public V get(Object key) { |
get方法的操作步骤如下:
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回。否则最后返回null
ForwardingNode的find方法:
1 | Node<K,V> find(int h, Object k) { |
size方法
1 | public int size() { |
对于size的计算,在扩容和addCount()方法中就已经处理了。JDK1.7是在调用size()方法采取计算,其实在并发集合中去计算size是没有多大意义的,因为size是实时在变的,只能计算某一刻的大小,但是某一刻太快了,人的感知是一个时间段,所以并不是很精确。
总结
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言:
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很高的,代替一定阈值的链表,这样形成一个最佳拍档
JDK1.8为什么用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点:
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据。
https://www.cnblogs.com/study-everyday/p/6430462.html#autoid-2-1-4
https://toutiao.io/posts/e53a9y/preview
http://wuzhaoyang.me/2016/09/05/java-collection-map-2.html

