Git是目前广泛使用的版本控制系统,一直以来我对Git的使用都停留在比较表面的层次,一旦涉及到版本回退、代码合并等操作就会遇到困难。本文是对Git日常使用的一个整理,用于加深对git的理解,方便需要时查阅。同时这也是我们小组培训时的材料。
基本介绍
版本控制系统是代码开发中不可或缺的工具,在git之前就存在多种版本控制工具,最著名的比如CVS、SVN。
Git的开发者是Linux的创建者Linus,最初Linus选择了一个商业的版本控制系统BitKeeper。后来因为种种问题BitKeeper公司停止了对Linux社区的免费使用权。于是Linus花了两周时间自己用C写了一个分布式版本控制系统,这就是Git。
Git与CVS和SVN最大的不同是后者是集中式的版本控制系统,而Git是分布式版本控制系统。
分布式版本控制系统可以没有“中央服务器”,每个人的电脑上都是一个完整的版本库,工作时理论上不需要联网。但是实际使用时通常有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
创建仓库
仓库,英文名repository,可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,Git可以跟踪每个文件的修改、删除,如果需要的话可以执行“还原”操作。
创建本地仓库
git不依赖网络就可以工作,因此可以直接在本地创建一个仓库来管理仓库中的文件。操作方式如下:
选择一个目录比如git-demo,执行git init,仓库就这样建好了。
仓库建好之后目录下多了一个.git目录,这个目录就是Git用来跟踪管理仓库的。
添加远程仓库
有了本地仓库,理论上就可以使用Git来管理我们的代码。不过为了多人协作的方便以及代码的安全,我们需要一台运行git的服务器来同步多人对仓库的修改,以及备份我们的代码。我们可以自己搭建一台git服务器,也可以直接使用现成的git服务器比如github。
首先注册github。创建ssh key并添加到github中。接着在github中创建一个新的仓库。获得新仓库的地址,比如:`[email protected]:wangqifox/git-demo.git`。
然后在本地仓库下执行git remote add origin [email protected]:wangqifox/git-demo.git。这样就把本地仓库和远程仓库关联起来了。此时远程仓库的名称是origin,这是Git默认的叫法,用户可以设置成别的名称。
从远程仓库克隆
如果已经有了一个远程仓库,那么就不用手动新建一个本地仓库,直接使用clone命令克隆远程仓库到本地:
git clone [email protected]:wangqifox/git-demo.git
仓库管理
Git的基本概念
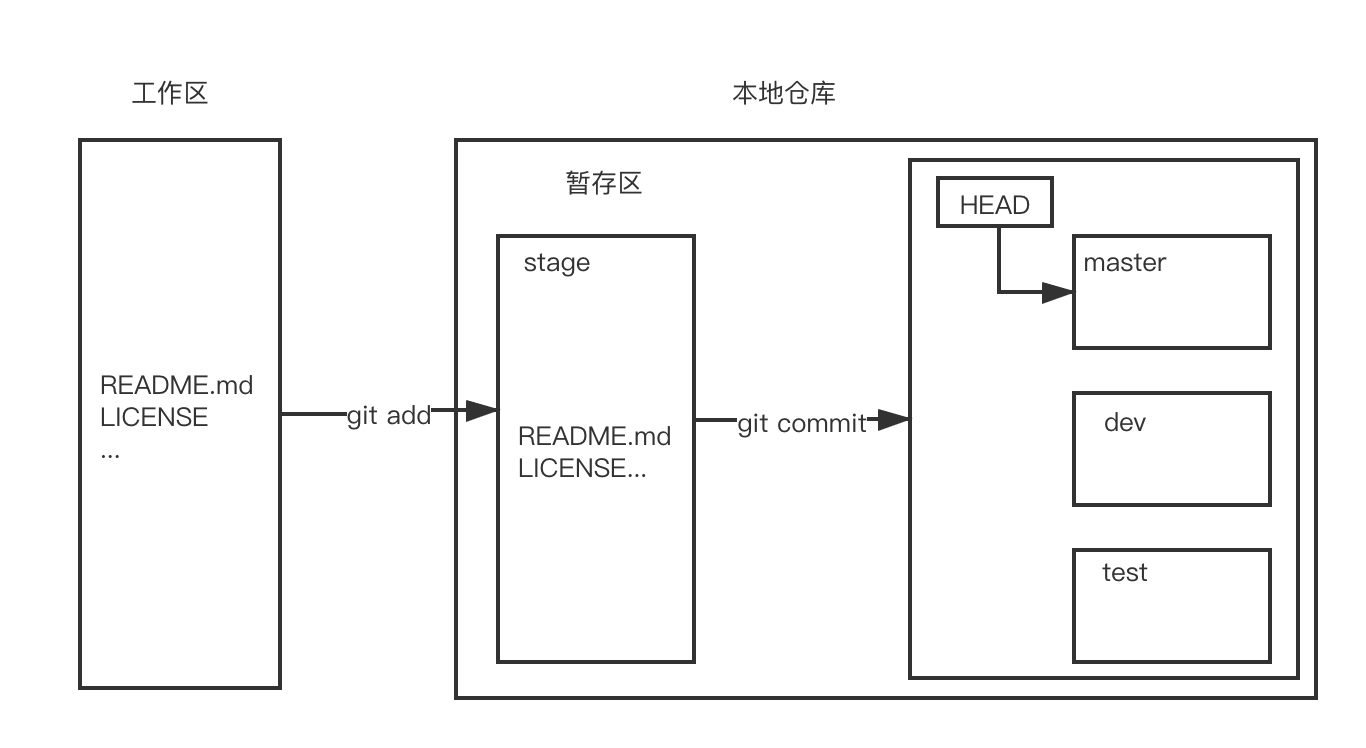
理解Git的各种操作,首先要知道Git的3个基本概念:工作区、暂存区、本地仓库。
工作区就是我们能看到的这个目录,对于文件的修改就在工作区中进行,对于工作区中的修改Git是无法追踪到的,即Git不会记录这些修改。
前面我们看到,仓库创建的时候生成了一个名为.git的隐藏目录,这个目录不属于工作区,它是Git的本地仓库。
.git目录中保存了很多东西,其中最重要的就是称为stage(或者index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。
使用Git来管理文件
了解了Git的基本概念之后,我们就可以使用Git来正式管理我们的文件。
在刚才的仓库git-demo中新建一个文件1.txt。此时文件1.txt处于工作区中,并没有添加到暂存区中,使用git status命令查看状态:
1 | $ git status |
可以看到,此时1.txt文件处于untracked的状态。
一般情况下,Git中的文件有两种状态:
未被追踪的文件(untracked):如果这个文件还未被纳入版本控制系统中,我们称之为“未被追踪的文件”。这就表示版本控制系统不能监视或者追踪它的改动。一般情况下未被追踪的文件会是那些新建的文件,或者是那些没有被纳入版本控制系统中的忽略文件。
已追踪的文件(tracked):所有那些已经被纳入版本控制系统的项目文件我们称之为“已追踪的文件”。Git会监视它们的任何改动,并且你可以提交或放弃对它的修改。
我们需要使用git add 1.txt命令将1.txt文件的修改添加到暂存区中。执行git add命令之后再使用git status命令查看状态:
1 | $ git status |
status命令显示新增了一个1.txt文件。git add命令实际上就是把要提交的所有修改放到暂存区。
修改放到暂存区之后,就可以使用git commit命令一次性把暂存区的所有修改提交到当前分支:
1 | $ git commit -m "add 1.txt" |
-m参数后面跟的是此时提交的注释。
高质量的注释
花一点时间写一个好的提交注释是非常值得的,这样可以让开发团队的其他成员非常容易地明白你做这次提交的目的和你的改动(过了一段时间对你自己也有帮助)。
针对你的改动写一个简短的注释标题(原则上不要超过50个字符),然后使用一个空行来分隔注释的内容。注释的内容要尽可能的详细并且要能回答以下几个问题:为什么要做这次修改?与上一个版本相比你到底改动了什么?
如果你有一个很长的提交注释,并且注释中包含很多段落,那你就不需要使用-m参数了,Git会为你打开一个文本编辑器(具体打开哪个文本编辑器,你可以在core.editor设置它),在文本编辑器中,你可以仔细写上此时提交的注释。
什么才是一个好的提交
一个高质量的手动提交对你的项目和你自己是非常有意义的。什么才是一个好的提交呢?在这里有一些基本的原则:提交要仅仅对应一个相关的改动
首先,一次提交应该仅仅只对应一个相关的改动。不要把那些互相毫无关联的改动打包在同一次提交中。如果这次提交出现了什么问题,解决和撤销它将是非常困难的。完整的提交
千万不要提交那些没有完全完成的改动。如果你想要临时保存一下你当前的工作,例如一个类似于剪贴板(clipboard)的功能,你可以使用Git提供的“Stash”功能。但是一定不要直接提交它。提交前测试
当你提交你的改动时,不要理所当然地认为你的改动永远正确。在你提交你的改动到你的仓库前,进行有效的测试是非常重要的。高质量的提交注释
一次高质量的提交需要一个好注释。最后,你须要养成一个频繁地进行提交的习惯。这样做将自然而然的让你避免一个很庞大的提交,并且使这些提交可以更好只对映一个相关的改动。
使用git log命令我们可以看到我们所有提交的日志。
1 | $ git log |
每个提交都包括如下的元数据(metadata):
- Commit Id:每个提交都拥有一个唯一的ID。在一些集中式的版本控制系统中(比如
svn)会使用一个依次递加的版本号码,但是因为Git是分布式的版本控制系统,无法确定每个用户提交的先后顺序,因此它采用这种唯一的哈希编码来标识一次提交。在大多数项目中,这个哈希编码的前七位字符就已经能足够代表一个唯一的提交ID了,一般我们都会用这个简短的7位 ID 来代表一个提交。 - Author Name & Email:提交人的姓名和电子邮件
- Date:提交日期
- Commit Message:提交注释
注意,Git管理的其实不是文件,而是修改。新增一行是一个修改,删除一行是一个修改,创建一个文件也是一个修改。
我们可以简单做个验证:
- 在
1.txt文件中添加一行11111 - 执行
git add 1.txt将文件添加到暂存区 - 再在
1.txt文件中添加一行22222
此时再查看状态:
1 | $ git status |
可以看到有两次修改,一次修改被记录在暂存区中,另一次修改并没有被保存到暂存区中。
这时执行git commit命令,再查看状态
1 | $ git commit -m "modify 1.txt" |
发现第二次的修改并没有被提交到版本库中。
撤销修改
撤销修改分为两种情况:
一种情况是修改并没有保存到暂存区,查看状态:
1 | $ git status |
可以发现,Git已经提示你了,使用git restore <file>命令可以丢弃工作区的修改。这个命令让文件回到最近一次git commit或git add时的状态。
1 | $ git restore 1.txt |
可以看到文件已经复原了。
注意,老版本的git撤销工作区的修改使用git checkout -- file命令
另一种情况是修改已经保存到暂存区了,查看状态:
1 | $ git status |
Git提示我们使用git restore --staged <file>命令可以把暂存区的修改撤销掉(unstage):
1 | $ git restore --staged 1.txt |
执行之后暂存区的修改被放回到工作区。
注意,老版本的git撤销暂存区的修改使用git reset HEAD <file>命令
版本回退
如果我们的修改不止保存到了暂存区,还从暂存区提交了仓库,那么我们需要使用版本回退来撤销这些修改。
每当我们执行git commit方法将暂存区的修改提交到仓库,仓库中就保存了这个修改的一个“版本”。一旦我们需要恢复到某一个“版本”,我们就可以执行git reset命令回退到那个“版本”。
首先使用git log命令查看提交历史,如果嫌输出信息太多,可以加上--pretty=oneline参数:
1 | $ git log --pretty=oneline |
左边显示的commit id(版本号),右边显示的是提交时的注释。
在Git中HEAD表示当前版本,指向的commit id是ae6e66aededc8535066d43aafad2694892b7e140。上一个版本表示成HEAD^,上上个版本就是HEAD^^,如果是往上100个版本写成HEAD~100。
所以想要回退到上一个版本我们就可以执行命令:
git reset --hard HEAD^
也可以直接指定上个版本的commit id:
git reset --hard d4af13be6
查看状态,可以看到已经回退到上一个版本了:
1 | $ git log --pretty=oneline |
可以看到最新的那个版本在log中已经看不到了,想要返回最新的版本怎么办呢:
如果还记得commit id,那很简单,执行git reset --hard ae6e66a就可以了。
如果不记得commit id了,我们还可以执行git reflog命令来找到那一次的commit id。git reflog命令记录了你的每次命令。
回退之后使用以下命令推送到远程仓库:
1 | git push origin HEAD --force |
--hard、--soft、--mixed参数的区别:
--soft参数表示将本地版本库的头指针全部重置到指定版本,且将这次提交之后的所有变动都移动到暂存区。
假设我们在Git中提交了多个文件,提交记录如下:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
此时执行git reset --soft:
1 | $ git reset --soft 640047c |
我们看到执行git reset --soft命令后,HEAD指针指向了指定的提交,该提交之后的修改都被放到了暂存区中。
--mixed参数与--soft参数的区别在于git reset --mixed命令执行之后,该提交之后的修改不会放在暂存区中:
1 | $ git reset --mixed 640047c |
--hard参数不仅仅将本地版本库的头指针全部重置到指定版本,也会重置暂存区,并且会将工作区的代码也回退到这个版本:
1 | $ git reset --hard 640047c |
revert命令
git revert <commit>命令也能起到回退版本的作用,不同之处在于:
reset是向前移动指针,revert是创建一个提交来覆盖当前的提交,指针向后移动。revert仅仅是撤销某次提交,而reset会撤销某个提交点之后所有的提交。
1 | $ git revert 1c7e430 |
此时工作区中6.txt文件被删除,说明Git撤销了1c7e430这一次的提交,而这之后的所有提交并没有被撤销。
忽略文件
通常我们在开发过程中都会有一些文件或者目录是不想纳入版本控制系统的,比如Java开发中生成的.class、.jar文件和target目录。
哪些文件需要被忽略呢?一个最简单的分辨方法就是,那些在你开发项目过程中自己生成的文件。例如,临时文件,日志和缓存文件等。
还有其他的例子,比如那些为编译代码所提供的密码或者个人设置文件。
这个链接:https://github.com/github/gitignore可以帮助你更好地了解在不同的项目和开发平台上哪些内容不需要纳入版本控制中去。
如果我们要手动管理这些被忽略的文件,就必须非常小心翼翼,确保每次操作这些文件都不被保存到暂存区进而提交到版本库。好在Git提供了自动管理这些被忽略文件的机制,我们只需要在工作目录中创建一个称为.gitignore的文件,并在此文件中加入被忽略的文件和目录:
- 忽略一个特定的文件:给出从项目根目录开始的路径和文件名,例如
path/to/file.ext - 忽略项目下所有这个名字的文件:只要给出文件的全名,不要包括任何路径,例如
filename.ext - 忽略项目下所有这个类型的文件:例如
*.ext - 忽略一个特定目录下的所有文件:例如
path/to/folder/*
在一个项目开始之前,最好首先定义好.gitignore文件。因为一旦某个文件被提交了,即使把它写入到.gitignore文件中,这个文件也不会被忽略。
如果我们创建一个文件叫canIgnore.txt并将它提交到版本库中:
1 | $ touch canIgnore.txt |
然后我们将canIgnore.txt添加到.gitignore文件中。
此时再修改canIgnore.txt文件,Git不会忽略这个修改:
1 | $ git status |
此时如果要忽略掉对该文件的修改,我们只能手动将其从Git的版本库中删除,然后提交:
1 | $ git rm --cached canIgnore.txt |
这样对canIgnore.txt文件的任何修改都会被Git忽略。
分支管理
在我们开发实际项目的过程中,如果我们提交没有开发完成的代码,会导致整个项目处于不稳定的状态,甚至别人pull了代码后没法开发了。但是如果等代码全部开发完再提交,又存在丢失每天进度的风险。
因此我们需要不同的分支来管理代码。我们可以在不同的分支上开发并提交,直到开发完毕后,再合并到原来的分支上。
创建与合并分支
在Git里有一个默认的主分支,即master分支。我们在git log命令中可以看到HEAD指向的就是当前的master分支,master指向最近的提交。
到目前为止,我们在master分支上一共有5次提交。此时master分支是一条线,master指向最新的提交,HEAD指向master。这样就能确定当前分支,以及当前分支的提交点。
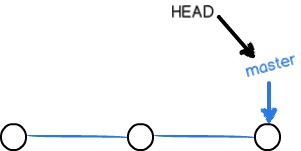
每次提交,master分支都会向前移动一步,这样,随着不断提交,master分支也会越来越长。
现在我们来创建一个名为dev的分支:
1 | git switch -c dev |
git switch命令加上-c参数表示创建并切换,相当于以下两条命令:
1 | git branch dev |
注意,在老版本git上使用git checkout -b <branch>来创建并切换分支
使用git branch命令查看当前分支,此命令会列出所有分支,当前分支前面会标一个*号:
1 | $ git branch |
此时,Git新建了一个指针叫dev,指向master相同的提交。HEAD指向dev,表示当前分支在dev上。
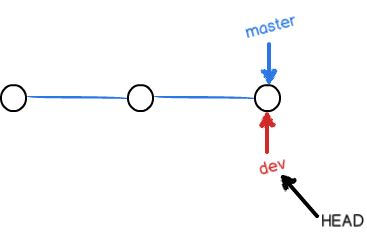
从现在开始,对工作区的修改和提交就是针对dev分支了。修改1.txt文件并提交。
当我们新提交一次后,dev指针往前移动一步,而master指针不变:
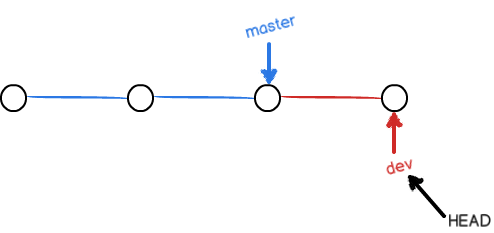
假如我们在dev上的工作完成了,就可以把dev合并到master上。
首先切换回master分支:
1 | $ git switch master |
切换回master分支后,我们发现刚才对1.txt文件的修改不见了,因为刚才的修改是在dev分支上完成的,而此时master分支此时还指向原来的提交点。
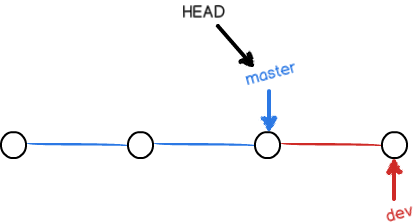
现在我们把dev分支的修改合并到master分支上:
1 | $ git merge dev |
git merge用于合并执行分支到当前分支。注意上面的Fast-forward信息,Git告诉我们,这次合并是“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度非常快。
合并之后master和dev指向同一个提交点。
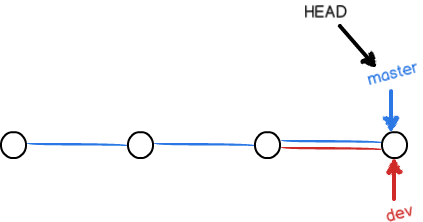
合并之后,可以删除dev分支:
1 | $ git branch -d dev |
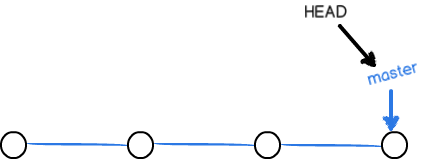
在查看branch,就只剩master分支了:
1 | $ git branch |
如果分支已经提交到远程仓库了,可以使用一下命令删除远程分支:
1 | git push origin --delete <branchName> |
解决冲突
合并分支往往不会向之前展示的那样顺利。
假设我们有两个分支feature1和master,这两个分支同时对1.txt文件的最后一行进行了修改并提交,于是我们的分支变成了这样:
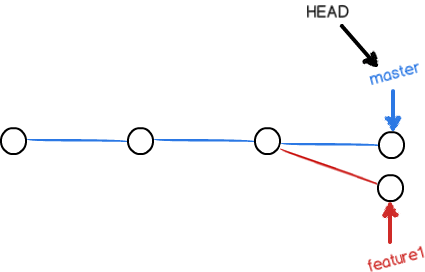
此时我们再尝试将feature1合并到master分支中:
1 | $ git merge feature1 |
Git告诉我们,1.txt文件存在冲突,自动合并失败,必须先手动解决冲突之后在提交。git status也告诉我们存在冲突:
1 | $ git status |
git status命令告诉我们为合并的文件1.txt,也可以执行git merge --abort命令放弃此次合并。
查看1.txt的内容:
1 | $ cat 1.txt |
Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容。我们解决冲突之后再提交:
1 | $ git add 1.txt |
现在master分支和feature1分支变成了下图所示:
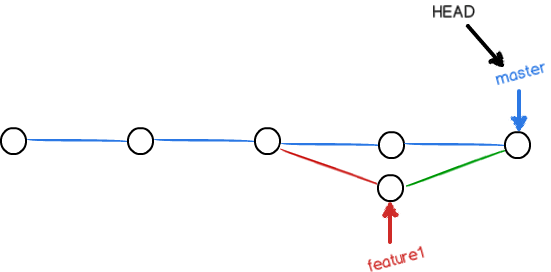
用带参数的git log也可以看到分支的合并情况:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
禁用Fast-forward模式
合并分支时,Git会尽量使用Fast-forward模式,合并之后的分支如下图所示:
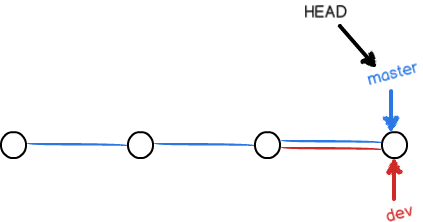
这种模式下,删除分支后会丢失掉分支信息。可以在合并分支时加上--no-ff参数来禁用Fast-forward模式:
1 | $ git switch -c dev |
因为本次合并要创建一个新的commit,所以加上-m参数,把commit描述写进去
不使用Fast-forward模式,合并之后的分支就像这样:
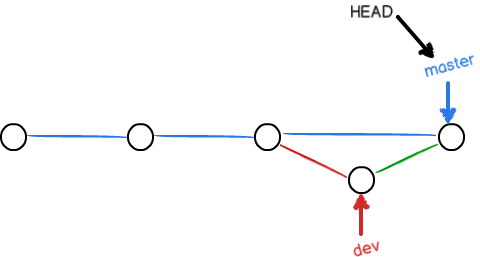
git stash && git cherry-pick
假设我们现在正在dev分支上开发工作只进行到一半,这时需要对master分支上的代码紧急修复一个bug。因为dev分支上的代码只开发到一半还没法提交,所以我们需要执行git stash命令来将当前的工作区“储藏”起来,等以后恢复现场后继续工作。
1 | $ git stash |
这时就可以去修复master分支的bug了。
1 | $ git switch master |
修复完成后,切换回master分支,并完成合并,最后删除bug分支:
1 | $ git switch master |
修复完bug,在回到dev分支继续开发:
1 | $ git switch dev |
执行git stash pop命令恢复刚才保存的工作现场。
1 | $ git stash pop |
我们知道dev分支是从早期的master分支分出来的,因此这个bug在dev分支也存在。那么如何修复dev分支上同样的bug呢?
我们只需要把刚才修复bug时提交的修改“复制”到dev分支就可以了。注意,我们只想复制修复bug时所提交的修改,并不是把整个master分支合并到dev分支。
Git专门提供了一个cherry-pick命令,让我们能复制一个特定的提交到当前分支。
1 | $ git cherry-pick 0580a5b |
注意,如果0580a5b这次提交修改的文件和当前dev修改了相同的文件,执行cherry-pick命令会失败,我们需要先提交dev的修改再执行:
1 | $ git cherry-pick 0580a5b |
此时执行cherry-pick命令会合并两次提交,如果有冲突我们还需要手动解决冲突。
远程仓库操作
前面介绍仓库创建的时候,介绍了远程仓库的添加与克隆。
在本地仓库添加了远程仓库之后,可以使用git remote -v命令查看远程仓库的情况:
1 | $ git remote -v |
可以看到,远程仓库origin的地址是:[email protected]:wangqifox/git-demo.git。如果没有推送权限,就看不到push的地址。
添加远程仓库之后,可以使用git push -u origin master命令将本地仓库的所有内容推送到远程仓库中。加上-u参数,Git不但会把本地的master分支的内容推送到远程仓库的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
再执行git push -u origin dev推送dev分支的修改到远程仓库。
以后如果要再推送提交到远程仓库就可以简单执行:git push,不用再使用完整的命令:git push origin master。
此时如果有另外的小伙伴clone我们的远程仓库,他只能看到master分支,看不到本地的dev分支。此时可以使用git branch -a查看所有的分支:
1 | $ git branch -a |
可以看到远程的dev分支,但是本地并没有该分支。我们需要手动创建该分支:
1 | $ git switch -c dev origin/dev |
接着使用git pull命令拉取远程分支最新的提交,如果执行失败:
1 | $ git pull |
原因是没有指定本地dev分支与远程origin/dev分支的链接。根据提示,设置dev和origin/dev的链接:
1 | $ git branch --set-upstream-to=origin/dev dev |
rebase操作
rebase用于代替merge操作。rebase操作相对于merge操作更加复杂,使用时需要慎重。
对于合并操作,Git会尽量使用Fast-forward模式,这样合并之后两个分支拥有完全相同的历史。
不过对于两个分支都有新的提交,或者手动禁用Fast-forward模式的情况下,Git会创建一个新的提交点,这个提交点整合了两个分支的修改。
这样一来,提交历史就有了多个分叉。有人并不喜欢这种分叉,相反,他们希望项目拥有一个单一的历史发展轨迹。比如一条直线。在历史纪录上没有迹象表明在某些时间它被分成过多个分支。
这就需要使用rebase命令。比如我们要在master分支上合并dev分支的提交,执行:
1 | git rebase dev |
首先,Git会“撤销”所有分支master上的那些在与分支dev的共同提交之后发生的提交。当然,Git 不会真的放弃这些提交,其实你可以把这些撤销的提交想像成“被暂时地存储”到另外的一个地方去了。
接下来它会整合那些在分支dev(这个我们想要整合的分支)上的还未整合的提交到分支master中。在这个时间点,这两个分支看起来会是一模一样的。
最后,那些在分支master的新的提交(也就是第一步中自动撤销掉的那些提交)会被重新应用到这个分支上,但是在不同的位置上,在那些从分支dev被整合过来的提交之后,它们就被rebased了。
整个项目开发轨迹看起来就像发生在一条直线上。
rebase操作最大的陷阱是它会改写历史记录。
前面我们看到最后一步分支master的提交会被重新添加到dev被整合过来的提交之后,这些master分支的提交虽然内容和原本的一样,但实际上是不同的提交。
如果还仅仅只是操作那些尚未发布的提交,重写历史记录本身也没有什么很大的问题。但是如果你重写了已经发布到公共服务器上的提交历史,这样做就非常危险了。其他的开发者可能已经上原始提交的基础上开始工作了,此时通过rebase操作删除了这个原始提交将是非常可怕的。
因此你应该只使用rebase来清理你的本地工作,千万不要尝试着对那些已经被发布的提交进行这个操作。
标签管理
标签(tag)其实就是对某一个提交赋予一个有意义的名称。原因是commit id是一串无意义的字符串,非常不好记。
通常在发布一个版本时,我们会对那个时刻的版本打一个标签。这样在将来要取出某个版本时,只需要将对应标签的版本取出来就可以了。
对当前版本打标签非常简单,切换到需要打标签的分支上,然后执行git tag <name>就可以了:
1 | $ git switch master |
默认标签是打在最新提交的commit上的。如果需要对历史提交打标签,只需要找到对应的commit id,然后执行:
1 | $ git tag v0.9 edf9717 |
使用git tag查看标签:
1 | $ git tag |
注意,标签不是按时间顺序列出,而是按字母排序的。可以使用git show <tagname>查看标签信息:
1 | $ git show v0.9 |
还可以创建带有说明的标签,用-a指定标签名,-m指定说明文字:
1 | $ git tag -a v0.1 -m "version 0.1 released" 000d967 |
如果标签打错了,也可以删除:
1 | $ git tag -d v0.1 |
因为创建的标签都只存储在本地,不会自动推送到远程。所以,打错的标签可以在本地安全删除。
如果要推送某个标签到远程,使用命令git push origin <tagname>:
1 | $ git push origin v1.0 |
或者,一次性推送全部尚未推送到远程的本地标签:
1 | $ git push origin --tags |
如果标签已经推送到远程,要删除远程标签就麻烦一点,先从本地删除:
1 | $ git tag -d v0.9 |
然后,从远程删除。删除命令也是push,但是格式如下:
1 | git push origin :refs/tags/v0.9 |
或者
1 | git push origin --delete tag <tagName> |
Commit message规范
统一团队的Commit message非常有必要,方便后续的代码review,版本回退,版本发布等等。
目前规范使用较多的是Angular 团队的规范,它的message格式如下:
1 | <type>(<scope>): <subject> |
每次提交,Commit message都包含三个部分:Header、Body、Footter。其中Header是必需的,Body和Footer可以省略。不管是哪一个部分,任何一行都不得超过72个字符(或100个字符)。这是为了避免自动换行影响美观。
Header部分只有一行,包括三个字段:type(必需)、scope(可选)、subject(必需)。
type
type用于说明commit的类别,可以有以下标识:
feat: 新增featurefix: 修复bugdocs: 仅仅修改了文档,比如README, CHANGELOG, CONTRIBUTE等等style: 仅仅修改了空格、格式缩进、逗号等等,不改变代码逻辑refactor: 代码重构,没有加新功能或者修复bugperf: 优化相关,比如提升性能、体验test: 测试用例,包括单元测试、集成测试等build: 改变构建流程、或者增加依赖库、工具等ci: 对持续集成工具的配置或者脚本的修改(比如:Travis, Circle, BrowserStack, SauceLabs)chore: 其他不影响src或test文件的修改revert: 回滚到上一个版本
scope
scope用于说明commit影响的范围,比如数据层、控制层、视图层等等,视项目不同而不同。
subject
subject是commit目的的简短描述,不超过50个字符:
- 以动词开头,使用第一人称现在时,比如change,而不是changed或changes
- 第一个字母小写
- 结尾不加句号
Body部分是对本次commit的详细描述,可以分成多行,有两个注意点:
- 使用第一人称现在时,比如使用change而不是changed或changes。
- 应该说明代码变动的动机,以及与以前行为的对比。
Footer
Footer部分只用于两种情况
- 不兼容变动
如果当前代码与上一个版本不兼容,则Footer部分以BREAKING CHANGE开头,后面是对变动的描述、以及变动理由和迁移方法。
- 关闭Issue
如果当前commit针对某个issue,那么可以在Footer部分关闭这个issue。
Closes #234
也可以一次关闭多个issue。
Closes #123, #245, #992
Commitizen: 替代你的 git commit
commit规范写的再好,也有可能因为开发人员的疏忽而破坏掉规范,最好的方法就是通过工具来生成和约束。
这里借助两个工具:
commitizen/cz-cli:我们借助它提供的
git cz命令来替代我们的git commit命令,帮助我们生成符合规范的commit message。cz-conventional-changelog:它用来为
commitizen指定一个Adapter,使得commitizen按照我们指定的规范帮助我们生成commit message。
全局安装
1 | npm install -g commitizen cz-conventional-changelog |
安装过后,可以在项目中执行git cz或者npm run commit,效果如下:
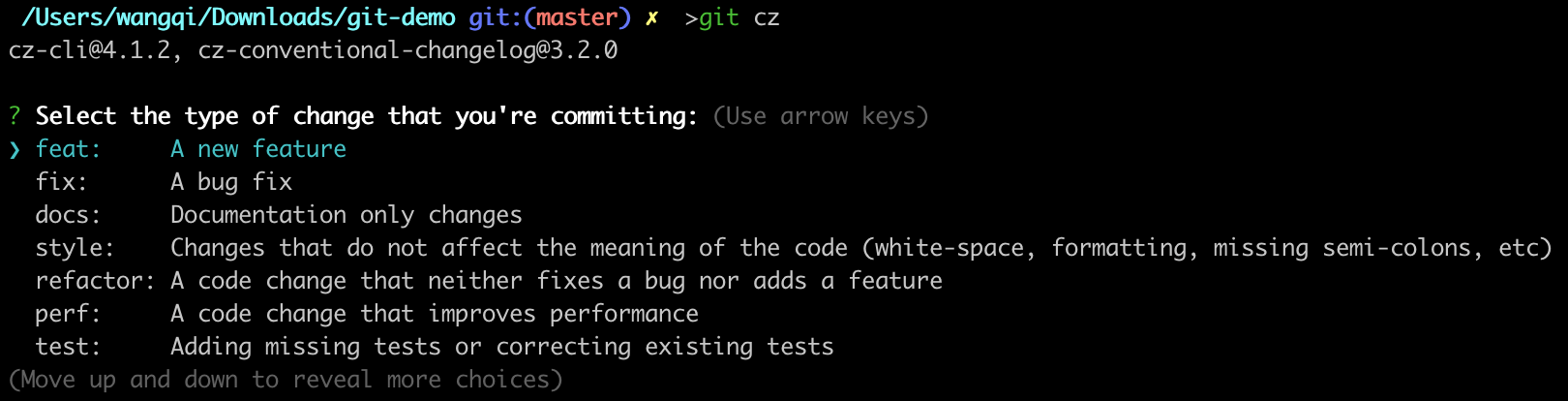
生成Change log
如果所有的commit都符合Angular格式,那么发布新版本时,Change log就可以用脚本自动生成。
生成的文档包括以下3个部分:
- New features
- Bug fixes
- Breaking changes.
每个部分都会罗列相关的commit,并且有指向这些commit的链接。当然,生成的文档允许手动修改,所以发布前,你还可以添加其他内容。
conventional-changelog就是生成Change log的工具,安装conventional-changelog-cli:
1 | npm install -g conventional-changelog-cli |
生成Change log有以下两种选择:
1 | # 不会覆盖以前的 Change log,只会在 CHANGELOG.md 的头部加上自从上次发布以来的变动 |
https://www.liaoxuefeng.com/wiki/896043488029600
https://juejin.im/post/5eeac089e51d457421362edf
https://www.git-tower.com/learn/git/ebook/cn/command-line/advanced-topics/rebase
https://www.git-tower.com/learn/git/ebook/cn/command-line/basics/starting-with-an-unversioned-project
https://www.jianshu.com/p/952d83fc5bc8
https://oschina.gitee.io/learn-git-branching/
https://juejin.im/post/5afc5242f265da0b7f44bee4
https://www.ruanyifeng.com/blog/2016/01/commit_message_change_log.html
https://juejin.im/post/5bd2debfe51d457abc710b57

