异常是Java中非常常用的功能,它可以简化代码,并且增强代码的安全性。异常处理是指程序不正常时的处理方式。具体来说,异常机制提供了程序退出的安全通道。当出现错误后,程序执行流程发生改变,程序的控制权转移到异常处理器。
异常的一般性语法为:
1 | try { |
异常体系
Java异常体系的简单结构图:
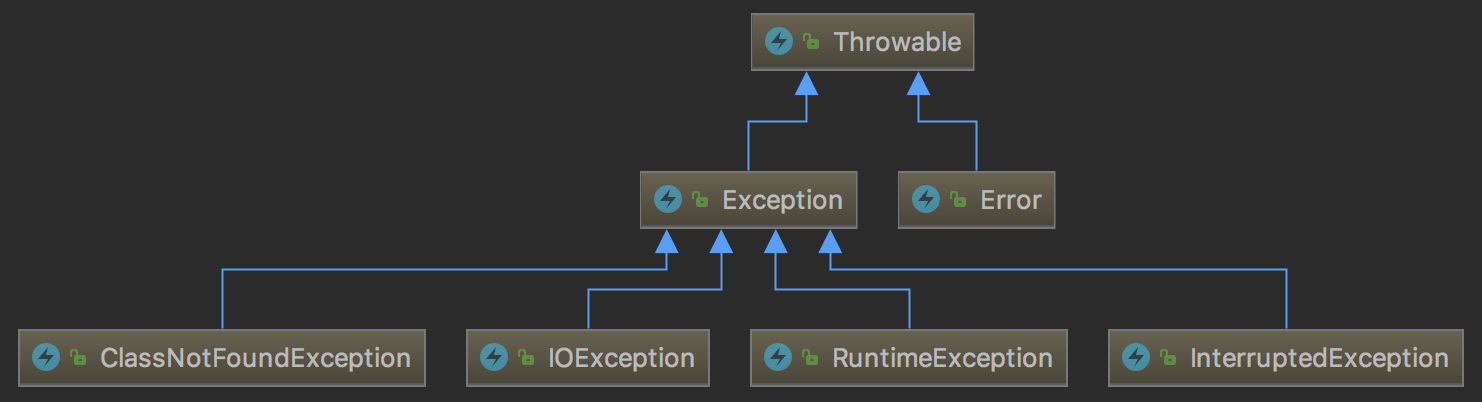
Throwable类是整个Java异常体系的超类,所有的异常类都派生自这个类。包含Error和Exception两个直接子类。Error表示程序在运行期间出现了十分严重,不可恢复的错误,在这种情况下应用程序只能中止运行,例如Java虚拟机出现错误。在程序中不用捕获Error类型的异常。一般情况下,在程序中也不应该抛出Error类型的异常。Exception是应用层面上最顶层的异常类,包含RuntimeException(运行时异常)和Checked Exception(受检异常)。RuntimeException是一种Unchecked Exception,即表示编译器不会检查程序是否对RuntimeException作了处理,在程序中不必捕获RuntimeException类型的异常,也不必在方法体声明抛出RuntimeException类。一般来说,RuntimeException发生的时候,表示程序中出现了编程错误,所以应该找出错误修改程序,而不是去捕获RuntimeException。常见的RuntimeException有NullPointException、ClassCastException、IllegalArgumentException、IndexOutOfBoundException等。Checked Exception是相对于Unchecked Exception而言的,Java中并没有一个名为Checked Exception的类。它是编程中使用最多的Exception,所有继承自Exception并且不是RuntimeException的异常都是Checked Exception。Java语言规定必须对Checked Exception做处理,编译器会对此做检查,要么在方法体中声明抛出Checked Exception,要么使用catch语句捕获Checked Exception进行处理,不然不能通过编译。常用的Checked Exception有IOException、ClassNotFoundException等。
异常有以下几个特点:
- 无论是受检异常(
Checked Exception)还是运行时异常(Runtime Exception),如果异常没有被应用程序捕获,那么最终这个异常会交由JVM来进行处理。会得到两个结果:异常触发点后面的代码将得不到运行,异常栈信息会通过标准错误流输出。 - 在catch异常时,如果有多个异常,那么是会有顺序要求的。子类型必须要在父类型之前进行catch,catch与分支逻辑是一致,如果父类型先被catch,那么后面catch的分支根本得不到运行机会。
- 如果在finally中返回值,那么在程序中抛出的异常信息将会被吞噬掉。这是一个非常值得注意的问题,因为异常信息是非常重要的,在出现问题时,我们通常凭它来查找问题。如果编码不小心而导致异常被吞噬,排查起来是相当困难的,这将是一个大隐患。
- 必须要对底层抛出来的受检异常进行处理,处理方式有
try...catch...或者向上抛出(throws),否则程序无法通过编译。 - 如果我们试图去捕获一个未被抛出的受检异常,程序将无法通过编译(
Exception除外) - 运行时异常(
runtime exception)与受检异常(checked exception)的最大区别是不强制对抛出的异常进行处理。所有的运行时异常都继承自RuntimeException。如果抛出的是运行时异常,就算不捕获这个异常,程序也可以编译通过。
正确使用异常
- 针对不同的异常采取合适的、正确的异常处理方式,不要遇到任何异常都
printTrace()或者打印一个日志 - catch时指定具体的异常。不要一股脑地catch Exception,具体的异常应该单独catch住,越具体的异常越早catch
- 如果涉及到资源的关闭,应该将关闭资源的代码写在finally代码块内
- try的范围应该尽量小,最好就是try住抛出异常的那个方法即可
重写Exception的fillInStackTrace方法
默认情况下,在程序抛出异常时,会调用fillInStackTrace()方法填充堆栈信息,代码如下所示:
1 | public synchronized Throwable fillInStackTrace() { |
fillInStackTrace()方法会通过调用private native Throwable fillInStackTrace(int dummy)这个本地方法来获取当前线程的堆栈信息,这是一个非常耗时的操作。如果我们仅仅需要用到异常的传播性质,而不关心异常的堆栈信息,那么完全可以通过重写fillInStackTrace()方法。实例如下:
1 | public class MyException extends Exception { |
为了对fillInStackTrace的性能有个了解,我们来对比一下有无fillInStackTrace两种情况的耗时。代码如下:
1 | public class FillInStackTraceTest { |
其中Exception1中重写了fillInStackTrace函数,Exception2是一个普通的异常类。测试的方式就是在100个线程中循环执行,得到执行的时间。如图所示:

可以看到fillInStackTrace方法对性能的影响是巨大的。
异常处理原理
Java编译后,会在代码后附加异常表的形式来实现Java的异常处理及finally机制。在JDK1.4.2之前,Javac编译器使用jsr和ret指令来实现finally语句,但是1.4.2之后自动在每段可能的分支路径后将finally语句块内容冗余生成一遍来实现。JDK1.7及之后版本,则完全禁止在Class文件中使用jsr和ret指令。
属性表(attribute_info)可以存在于Class文件、字段表、方法表中,用于描述某些场景的专有信息。属性表中有个Code属性,该属性在方法表中使用,Java程序方法体中的代码被编译成的字节码指令存储在Code属性中。而异常表(exception_table)则是存储在Code属性表中的一个结构,这个结构是可选的。
异常表结构如下表所示:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | start_pc | 1 |
| u2 | end_pc | 1 |
| u2 | handler_pc | 1 |
| u2 | catch_type | 1 |
异常表包含四个字段,如果当字节码在第start_pc行到end_pc行之间出现了类型为catch_type或者其子类的异常(catch_type为指向一个CONSTANT_Class_info型常量的索引),则跳转到第handler_pc行执行。如果catch_type为0,表示任意异常情况都需要转到handler_pc处进行处理。
处理异常机制
如上面所说,每个类编译后,都会跟随一个异常表。如果发生异常,首先在异常表中查找对应的行,如果找到,则跳转到异常处理代码执行,如果没有找到,则返回(执行finally之后),并copy异常的应用给父调用者,接着查询父调用的异常表,以此类推。
异常处理实例
对于Java源码:
1 | public class ExceptionClassCode { |
其编译后的字节码为:
1 | public int demo(); |
首先可以看到,对于finally,编译器将每个可能出现的分支后都放置了冗余。并且编译器生成了4个异常表记录,从Java代码的语义上讲,执行路径分别为:
- 如果try语句块中出现了属于Exception及其子类的异常,则跳转到catch处理
- 如果try语句块中出现了不属于Exception及其子类的异常,则跳转到finally处理
- 如果catch语句块中出现了任何异常,则跳转到finally处理
由此可以分析此段代码可能的返回结果:
- 如果没有出现异常,返回1
- 如果出现了Exception异常,返回2
- 如果出现了Exceptino以外的异常,非正常退出,没有返回
我们来分析字节码:
- 首先执行
0-4行。把整数1赋值给x,并且将此时x的值复制一个副本到本地变量表的Slot中(即returnValue)。这个Slot里面的值在ireturn指令执行前会被重新读到栈顶,作为返回值。 - 如果没有异常,则执行
5-7行,把x赋值为3,然后返回returnValue中保存的1,方法结束。 - 如果出现
java.lang.Exception异常,读取异常表发现应该执行第8行,pc寄存器指针指向第8行。8-16行就是把2赋值给x,然后把x赋值给returnValue,再将x赋值为3,然后将returnValue中的2读到操作栈顶返回。 - 如果出现了不属于
java.lang.Exception及其子类的异常,读取异常表发现应该执行第17行,pc寄存器指针指向第17行。17行开始把x赋值为3并且将栈顶的异常抛出,方法结束。
athrow是专门用于抛出异常的指令。这个指令大致的运作过程如下:
首先检查操作栈顶,这时栈顶必须存在一个reference类型的值,并且是java.lang.Throwable的子类(虚拟机规范中要求如果遇到null则当做NPE异常使用),然后暂时先把这个引用出栈,接着搜索本方法的异常表,找一下本方法中是否有能处理这个异常的handler,如果能找到合适的handler就会重新初始化PC寄存器指针指向此异常handler的第一个指令的偏移地址。接着把当前栈帧的操作栈清空,再把刚刚出栈的引用重新入栈。如果在当前方法中很悲剧的找不到handler,那只好把当前方法的栈帧出栈(这个栈是VM栈,不要和前面的操作栈搞混了,栈帧出栈就意味着当前方法退出),这个方法的调用者的栈帧就自然在这条线程VM栈的栈顶了,然后再对这个新的当前方法再做一次刚才做过的异常handler搜索,如果还是找不到,继续把这个栈帧踢掉,这样一直找,要么找到一个能使用的handler,转到这个handler的第一条指令开始继续执行,要么把VM栈的栈帧抛光了都没有找到期望的handler,这样的话这条线程就只好被迫终止、退出了。
https://blog.csdn.net/xialei199023/article/details/63251277
https://blog.liexing.me/2017/09/17/java-exception-table/
https://www.cnblogs.com/f-ck-need-u/p/8130361.html
https://my.oschina.net/suemi/blog/852542
http://www.importnew.com/14688.html

