在AI的应用中,GPU是无法绕过的设备。在Docker中调用GPU是AI算法部署时必然需要考虑的问题。
在docker容器中调用gpu,根据下面的步骤。
一共分为两步:
- 安装nvidia的gpu驱动
- 安装nvidia-docker2,将docker的runtime配置为
nvidia-container-runtime
使用nvidia-docker2
如果以下命令可以正常执行,说明docker可以正常调用gpu:
1 | docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi |
这种方式来调用gpu是官方推荐的方式。是需要安装nvidia-docker2。
直接挂载GPU设备
另一种方式是将gpu设备挂载到容器内部(前提是服务器已经正确安装了gpu驱动),在容器内部安装gpu需要驱动程序。
使用下面的Dockerfile来构建带gpu驱动的镜像。
1 | FROM ubuntu:18.04 |
构建镜像:
1 | docker build . -t wangqifox/gpu |
执行镜像时,将gpu相关的设备挂载到容器内部:
1 | docker run -it \ |
这样在容器内部就可以看到gpu了:
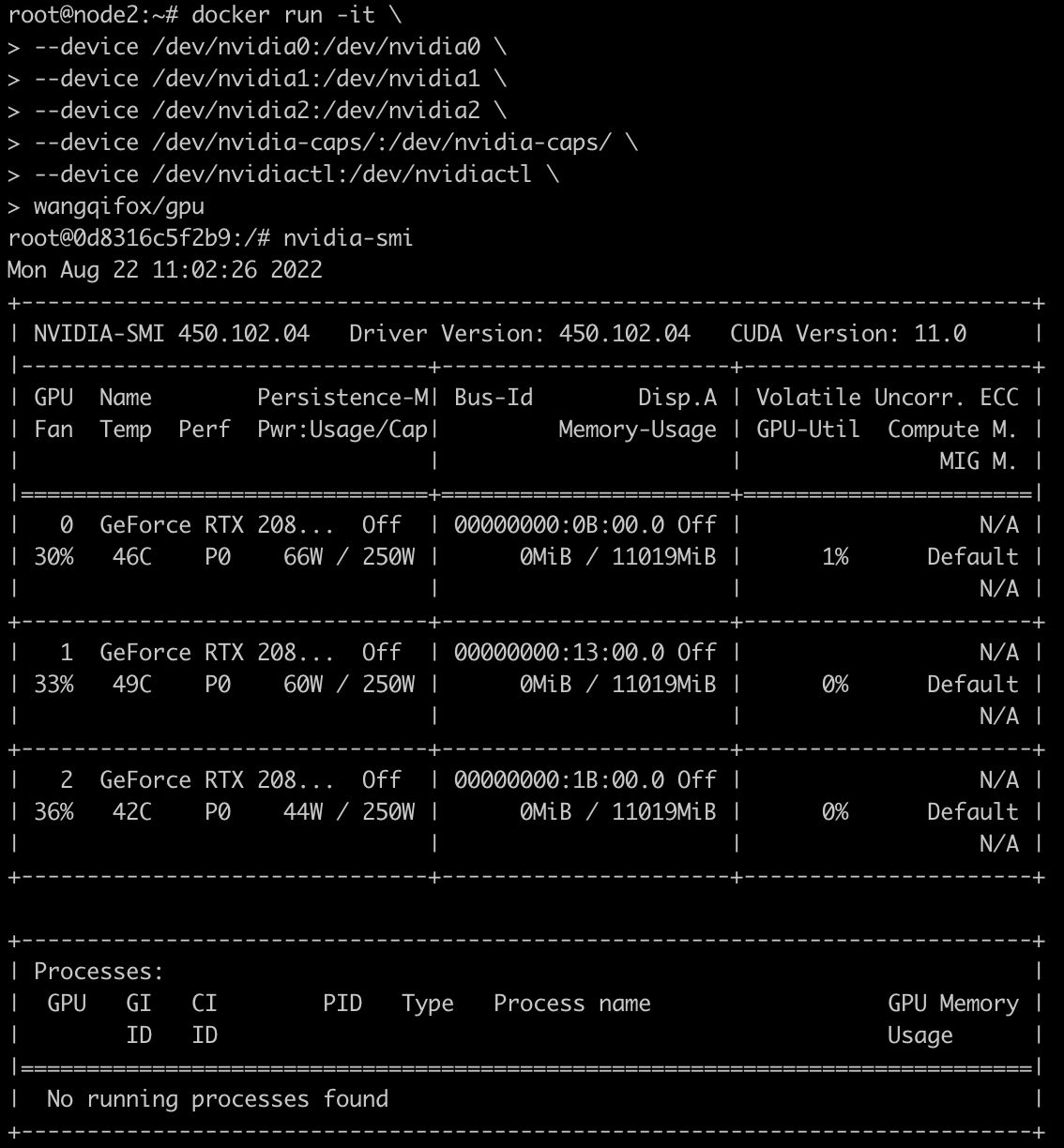
使用特权模式使用GPU
当然也可以使用特权模式来运行容器,通过特权模式容器具备了最高权限因此可以访问到宿主机中的gpu设备。特权模式不推荐在生产环境中使用:
1 | docker run -it --privileged wangqifox/gpu |
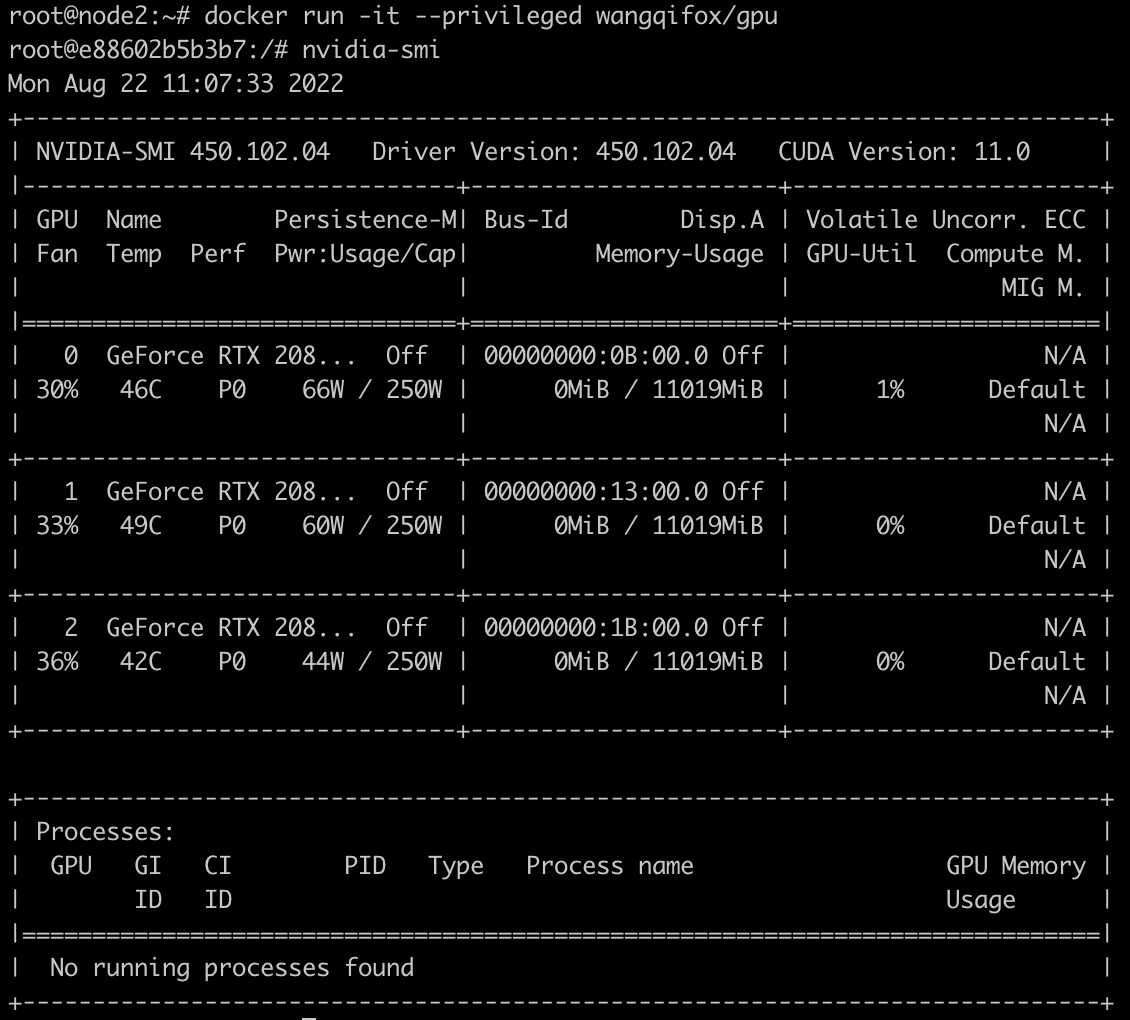
实际上,nvidia-docker也是采用挂载gpu设备、库文件、可执行文件的方式达到在容器中使用gpu的目的。
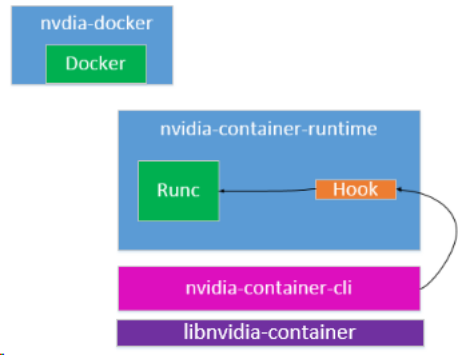
nvidia-container-runtime封装了runc,在容器启动之前会调用pre-start hook,这个hook会调用nvidia-container-cli,nvidia-container-cli会分析出需要映射的GPU设备、库文件、可执行文件,在容器启动后挂载到容器内部,达到配置好GPU环境的目的。
在nvidia-docker2中nvidia-docker命令行被简化,以shell脚本的形式进行了封装,nvidia-docker-plugin被废弃,改为通过在docker runc中添加hook的方式进行。将对UVM、NVML、devices等的管理提出来形成了libnvidia-container库。
安装驱动之后/dev/nvida-uvm设备不存在,参考https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#runfile-verifications。创建脚本,并设为开机启动:
1 |
|
https://github.com/NVIDIA/nvidia-docker/issues/871
https://gitlab.com/nvidia/container-images/driver/-/blob/master/ubuntu18.04/Dockerfile
https://www.cnblogs.com/oolo/p/11679733.html
http://www.uml.org.cn/yunjisuan/201901092.asp
https://cloud.tencent.com/developer/article/1496697
https://maple.link/2020/03/29/手动挂载Nvidia显卡到docker容器中/
https://xigang.github.io/2018/11/08/nvidia-container-runtime/
《NVIDIA Docker CUDA容器化原理分析》摘录
CUDA是由NVIDIA推出的通用并行计算架构,通过一些CUDA库提供了一系列API供应用程序调用。开发者可调用这些API充分利用GPU来处理图像,视频解码等。
CUDA API体系包括:CUDA函数库(CUDA Libraries),CUDA运行时API(CUDA Runtime API),CUDA驱动API(CUDA Driver API),结构图如下:
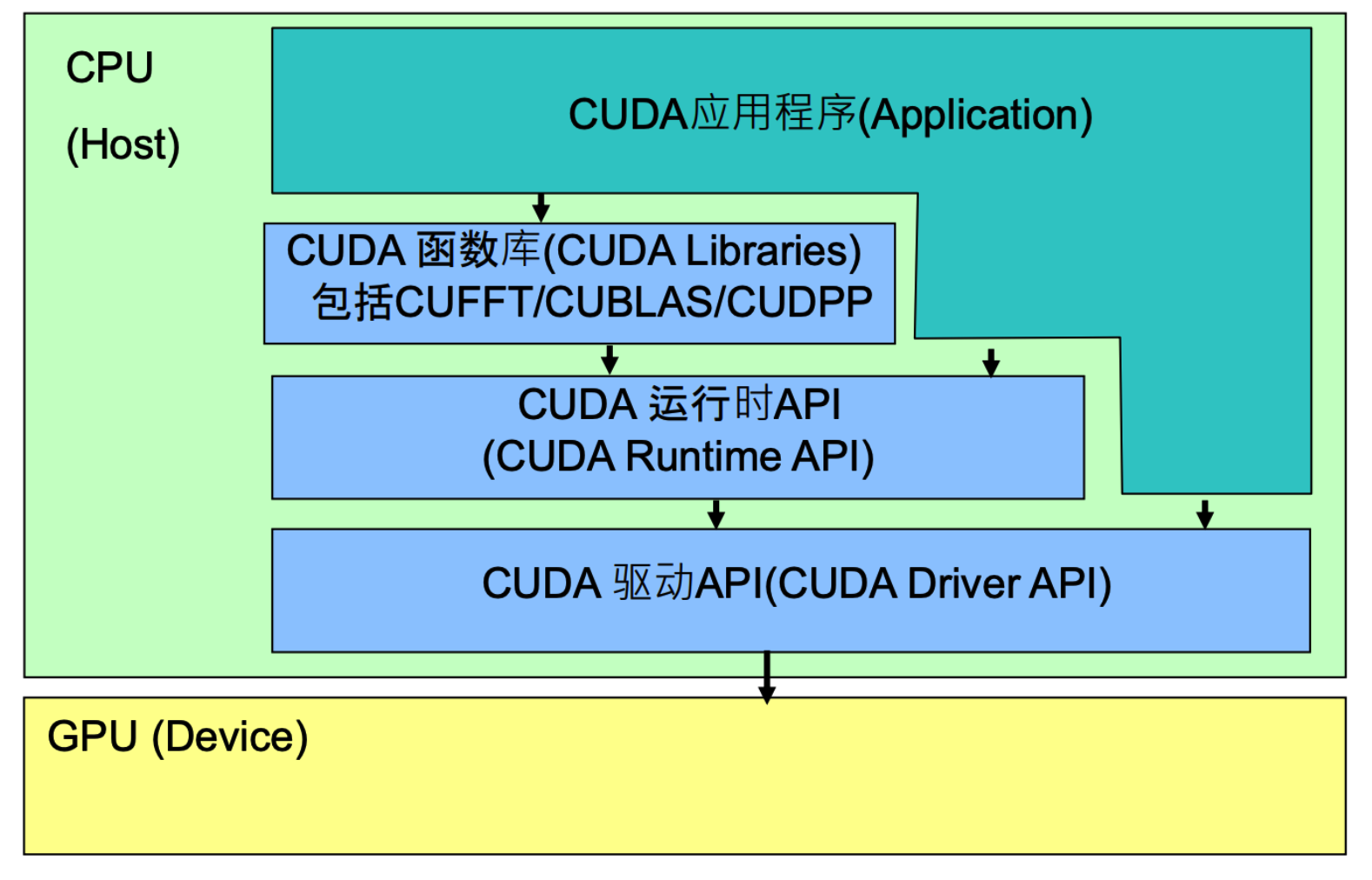
CUDA Driver API:GPU设备的抽象层,通过提供一系列接口来操作GPU设备,性能最好,但编程难度高,一般不会使用该方式开发应用程序。
CUDA Runtime API:对CUDA Driver API进行了一定的封装,调用该类API可简化编程过程,降低开发难度。
CUDA Libraries:是对CUDA Runtime API更高一层的封装,通常是一些成熟的高效函数库,开发者也可以自己封装一些函数库便于使用
应用程序可调用CUDA Libraries或者CUDA Runtime API来实现功能,当调用CUDA Libraries时,CUDA Libraries会调用相应的CUDA Runtime API,CUDA Runtime API再调用CUDA Driver API,CUDA API再操作GPU设备。
CUDA容器化的目标就是要能让应用程序可以在容器内调用CUDA API来操作GPU,因此需要实现:
- 在容器内应用程序可调用CUDA Runtime API和CUDA Libraries
- 在容器内能使用CUDA Driver相关库。因为CUDA Runtime API其实就是CUDA Driver API的封装,底层还是要调用到CUDA Driver API
- 在容器内可操作GPU设备
要在容器内操作GPU设备,需要将GPU设备挂载到容器里,Docker可通过—device挂载需要操作的设备,或者直接使用特权模式(不推荐)。
NVIDIA Docker是通过注入一个prestart的hook到容器中,在容器自定义命令启动前就将GPU设备挂载到容器中。至于要挂载哪些GPU,可通过NVIDIA_VISIBLE_DEVICES环境变量控制。
挂载GPU设备到容器后,还要在容器内可调用CUDA API。CUDA Runtime API和CUDA Libraries通常跟应用程序一起打包到镜像里,而CUDA Driver API是在宿主机里,需要将其挂载到容器里才能被使用。 NVIDIA Docker挂载CUDA Driver库文件到容器的方式和挂载GPU设备一样,都是在runtime hook里实现的。
接下来分析NVIDIA Docker中是如何实现将GPU Device和CUDA Driver挂载到容器中的。
NVIDIA Docker分两个版本,1.0版本通过docker volume将CUDA Driver挂载到容器里,应用程序要操作GPU,需要在LD_LIBRARY_PATH环境变量中配置CUDA Driver库所在路径。
2.0版本通过修改docker的runtime实现GPU设备和CUDA Driver挂载:
1 | root@gpu1:~# cat /etc/docker/daemon.json |
nvidia-container-runtime实现如下:
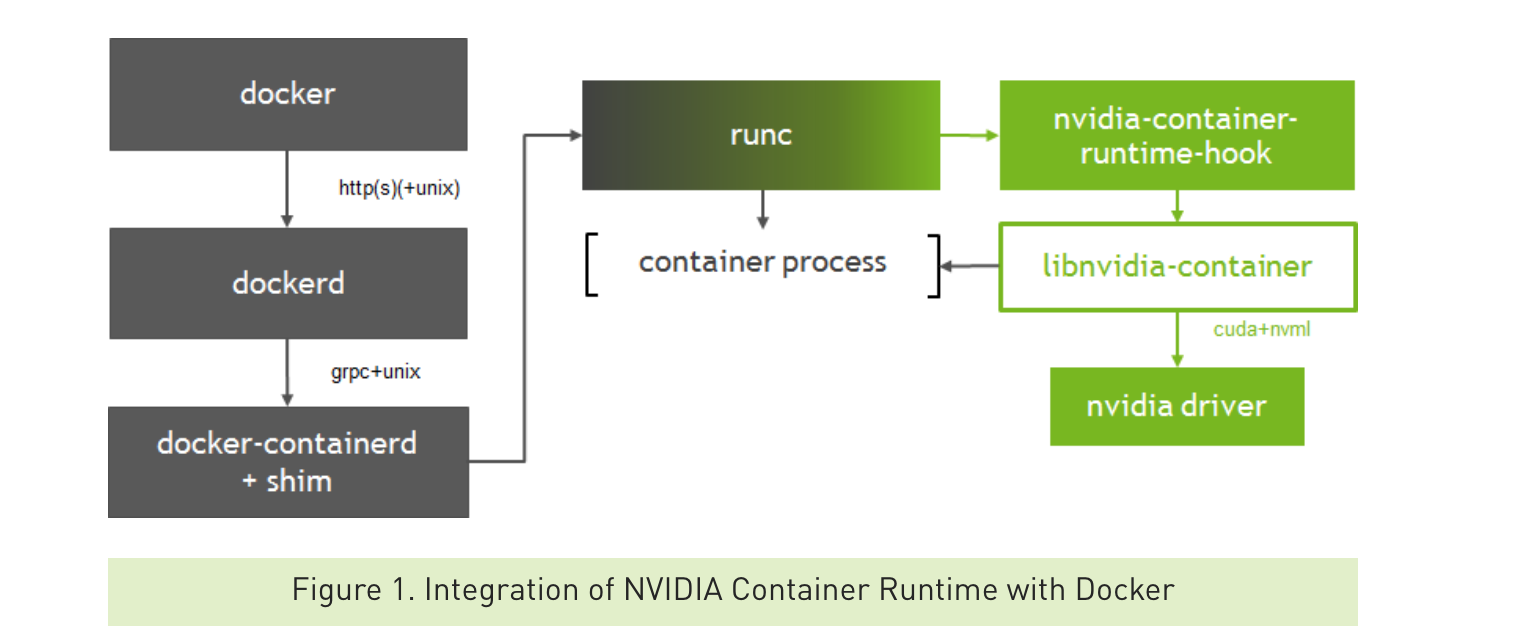
nvidia-container-runtime其实就是在runc基础上多实现了nvidia-container-runtime-hook,该hook是在容器启动后(Namespace已创建完成),容器自定义命令(Entrypoint)启动前执行。当检测到NVIDIA_VISIBLE_DEVICES环境变量时,会调用libnvidia-container挂载GPU Device和CUDA Driver。如果没有检测到NVIDIA_VISIBLE_DEVICES就会执行默认的runc。
libnvidia-container采用linux c mount --bind功能将CUDA Driver libraries/Binaries一个个挂载到容器里,而不是将整个目录挂载到容器中。
通过以下方式启动容器:
1 | docker run -it --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 bash |
执行mount命令,查看挂载情况。可以看到名为libnvidiaXXX.so的库文件以及nvidia-smi命令挂载到容器中,
1 | root@4650d9e9e22f:/# mount |
1 | root@4650d9e9e22f:/# env |

