基于ElasticSearch的搜索功能开发过程中,数据的实时同步是一个非常关键的步骤。
从代码的解耦角度来考虑,业务代码不会直接往ES写数据,而仅仅是查询ES。业务代码将数据更新到Mysql,然后由单独的同步程序同步到ES。我们采用的方式如下:
- 使用阿里开源的canal监听mysql的binlog
- 将binlog解析过的数据发送到Kafka
- 同步程序从Kafka中读数据
- 构造数据插入到ES中
这个流程的问题是:binlog每次输出单条数据,这样每次都只能往ES中插入或更新单条数据。在并发量大的场景下,ES的插入或修改出现瓶颈。
这个问题的解决方法是将单个的数据插入修改合并成批量操作,ES提供了BulkRequest方法来批量插入或更新数据。
HystrixCollapser
为了不对原先的流程大幅度修改,我们引入了Hystrix。Hystrix提供了请求合并功能,详见Hystrix(七)——请求合并。
首先新建一个示例来说明Hystrix请求合并的使用。以插入过程为例,首先继承HystrixCollapser创建一个命令合并器:
1 | public class InsertCommandCollapser extends HystrixCollapser<Void, Void, String> { |
新建InsertBatchCommand作为执行批量操作的命令
1 | public class InsertBatchCommand extends HystrixCommand<Void> { |
测试请求合并的效果:
1 | public class CollapserTest { |
如上所示,启动10000个线程来插入10000个id,结果如下图所示:
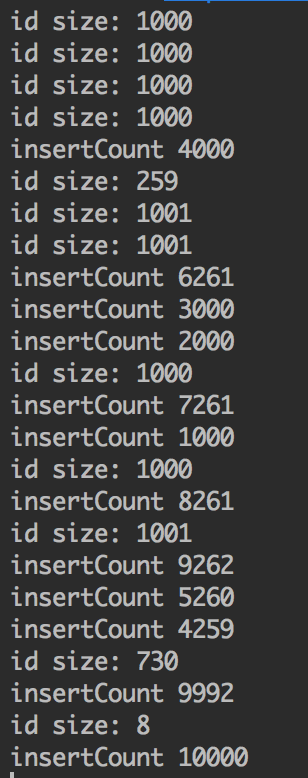
可以看到,通过调用InsertCommandCollapser,InsertBatchCommand命令接收到成批的id数据,使用这样批量的id数据我们就可以进行批量数据的插入。
修改InsertBatchCommand,构造BulkRequest批量处理数据(仅作为示例):
1 | public class InsertBatchCommand extends HystrixCommand<Void> { |
总结
跳出ES这个使用场景,请求合并是一个很重要的优化方案,经过合并之后可以减少数据处理的时间,减少网络请求等一系列开销。在多数情况都能带来显著的性能提高。
审视使用pipeline提升Redis的访问性能文章所描述的场景,其实pipeline也是一种请求合并操作,只不过这是redis自身所提供的功能。

